在机器学习领域,训练和测试数据共享相同分布的假设在现实场景中经常被违反,这需要有效的分布外(OOD)检测。本文提出了一种新的OOD检测方法,该方法利用KolmogorovArnold网络(KANs)独特的局部神经可塑性。与传统的多层感知器不同,KANs具有局部可塑性,允许它们在适应新任务的同时保留所学信息。我们的方法比较了经过训练的KAN与未经训练的KAN的激活模式来检测OOD样本。我们在图像和医学领域的基准测试中验证了我们的方法,与最先进的技术相比,展示了卓越的表现和鲁棒性。这些结果强调了KANs在提高不同环境下机器学习系统可靠性方面的潜力。
属于后处理方法,基于距离 #post-hoc
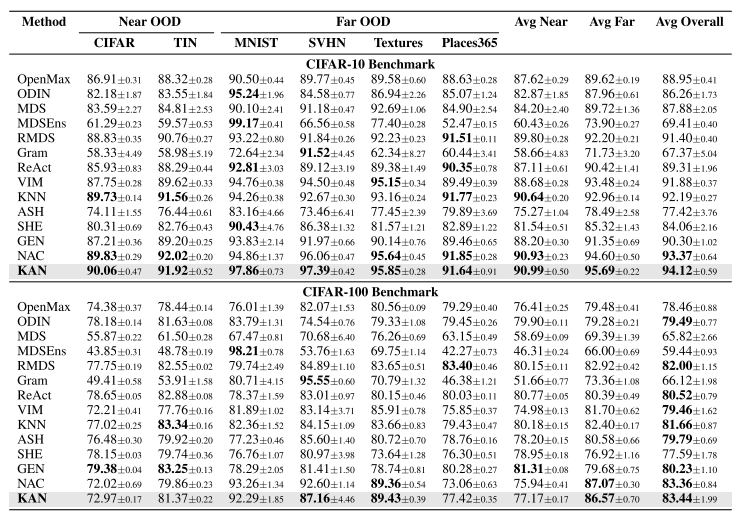
在OpenOOD benchmark上进行的实验:
alessandro-canevaro/KAN-OOD: Offical implementation of ICLR2025 paper Advancing Out-of-Distribution Detection via Local Neuroplasticity
ADVANCING OUT-OF-DISTRIBUTION DETECTION VIA LOCAL NEUROPLASTICITY
ICLR 2025
Introduction
大多数机器学习算法基于训练和测试数据共享相同分布,但是当遇到分布外的场景时这个假设会失效,影响模型准确性和可靠性。
KAN由于其基于样条的结构而表现出局部可塑性。这一特性确保了学习新任务只影响由训练数据激活的网络区域,从而保持了遥远和不相关区域的完整性。
如图1所示,我们的方法比较了两个相同初始化的KANs的激活模式:一个在分布内(InD)数据上训练,另一个未训练。OOD样本将主要触发已训练网络中未在学习阶段适应的区域,因此样本将产生更接近未训练网络的响应。
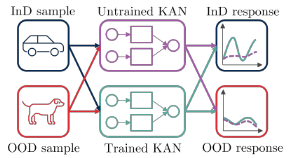
我的理解:上图看到OOD的结果比较平均,但ID的反应波动比较大
检测器将训练后的KAN模型与未训练的KAN模型的激活函数响应进行比较。差异较大的反应表明样品是InD,相似的反应表明样品是OOD。
KAN based OOD detection
Background
KAN是基于Kolmogorov-Arnold表示定理的神经网络架构。这个定理说明任何连续多元函数都可以表示为单个变量的连续函数的和。因此,KANs使用更简单的单变量组件近似高维函数,有效地解决了机器学习中的维度诅咒。
在实践中,KAN将多元函数分解为具有可学习系数的单变量b样条函数。设$x_{p}$为输入向量$\mathbf{x}∈R^{n_{in}}$的第p个分量(特征),设$y_q$为输出向量$\mathbf{y}∈R^{n_{out}}$的第q个分量(特征)。KAN层使用单变量函数的矩阵$Φ = {p,q}$将$\mathbf{x}$转换为$\mathbf{y}$,其中每个p,q都由b样条参数化。每个b样条由$G + k$个具有可学习系数$c_{p,q,i}$的b样条基函数的线性组合组成。样条阶表示为$k$(通常为k = 3),$G$为网格大小。
$$
y_{q} = \sum_{p}^{}\phi_{p,q}(x_{p}) \quad \text{with} \quad \phi_{p,q}(x_{p}) = \sum_{i=0}^{G+k}c_{p,q,i}B_{i}(x_{p})
$$
KAN层可以堆叠以构建更深的网络,允许跨多个阶段的复杂转换。残差连接通过可训练的权值和附加基函数为样条函数增加了灵活性,从而进一步提高了表现
KAN的局部神经可塑性由两个关键特性促进。首先,每个输入特征$x_{p}$都由它自己的激活函数${ϕ_{p,q} |∀q}$独立处理。其次,在反向传播期间,只有样本$x_p$附近的样条系数被修改,而激活函数的其他区域基本不变。
OOD + KAN
我们建议利用KAN的局部可塑性进行OOD检测。在训练期间看到的InD数据只影响网络的特定区域(样条网格系数)。通过确定一个区域是否包含InD数据并检查每个样本激活的区域,基于KAN的检测器可以区分InD和OOD样本。这种区分是通过比较训练后的激活函数的输出与训练前的值来实现的。步骤如下:
- 初始化:创造两个KAN,用ID数据集训练其中一个,另一个不训练
- 检测:
- 使用给定的样本x在两个网络上执行前向传递,并保存激活函数的输出$\phi_{p,q}^{trained}(x_{p}), \phi_{p,q}^{untrained}(x_{p}), \forall p,q$
- 计算二者的差距
$$\Delta_{p,q}(x_{p}) = |phi_{p,q}^{trained}(x_{p}),-\phi_{p,q}^{untrained}(x_{p})| = \sum_{i} |c_{p,q,i}^{trained} - c_{p,q,i}^{untrained}| \cdot B_{i}(x_{p})$$
其中,$|c_{p,q,i}^{trained} - c_{p,q,i}^{untrained}|$ 定义了网络中存储InD信息的位置,而 $B_{i}(x_{p})$ 作为掩码,制定了有样本$\mathbf{x}$激活的区域。因此将这两项相乘,提供了InD区域与给定样本之间重叠的定量度量。 - 分析差异矩阵 $\Delta$,OOD样本趋向于在$∆$矩阵中有较高比例的条目接近于零,因此$S(\mathbf{x})$分数对应低
$$
S(\mathbf{x}) = F_{score}(\Delta(\mathbf{x}))
$$
图2使用Liu等人(2024b)提出的玩具样例的修改版本说明了所提出算法的工作原理。该数据集是一个具有五个高斯峰的一维回归任务。我们使用其中的两个峰作为训练集和InD测试集,其余三个峰作为OOD测试集。这里的KAN模型由一个单层的一个输入和一个输出组成,即单个单变量函数$φ$具有200个样条系数。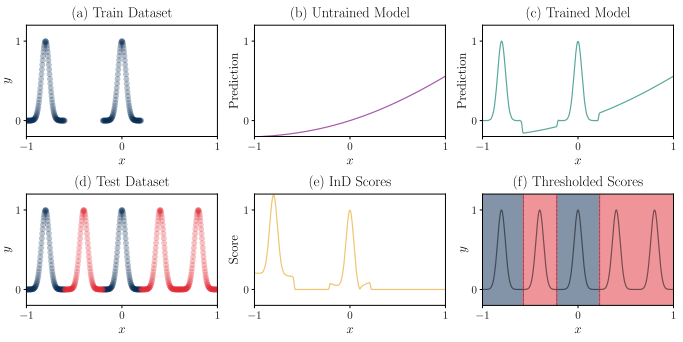
(a)训练数据集的可视化,显示输入和目标之间的关系。
(b)未经训练的KAN模型在整个输入范围内的响应。
(c)经过训练的KAN模型在整个输入范围内的响应。
(d)说明输入与目标的测试数据集,通过将训练数据集(InD)与剩余输入范围(OOD)上的三个附加高斯峰相结合而创建。
(e) InD score $S(\mathbf{x})\quad ∀\mathbf{x}∈[−1,1]$,使用中位数作为评分函数(Fscore)。
(f)对InD评分施加阈值(λ = 1e−3)后的最终结果:蓝色区域表示预测InD区域,红色区域表示预测OOD区域。
捕捉联合特征分布
类似集成模型的思路
与mlp一样,KAN能够处理多变量输入并产生多变量输出。然而,与mlp中激活函数接收所有输入的加权和不同的是,在KANs中,每个激活函数只接收单个输入。虽然这种特性使KAN检测器能够有效地捕获输入特征的边缘分布,但它也限制了其对特征联合分布建模的能力。
为了克服这一限制,我们建议对InD数据集进行分区,并为每个分区训练单独的KAN模型。这样,复杂的训练分布被分解成更小的部分,仅使用边缘特征分布就可以准确地描述这些部分。可以使用各种技术对数据集进行分区。一种简单而有效的方法是根据类标签拆分数据集。另一种方法是应用k-means这样的聚类算法(Lloyd, 1982),这种方法在没有类标签的情况下也有效,例如在回归任务中。
在形式上,数据集D被划分为P个不重叠的子集$D_1,D_2,\dots, D_p$。对于每个分区$D_i$,我们训练一个单独的检测器,记作$KAN_i$。虽然每个$KAN_i$的分区$D_i$不同,但训练任务总是相同的(例如,分类)。在推理过程中,我们通过汇总每个KAN模型的InD得分来计算样本$\mathbf{x}$的InD得分。令$∆^i(\mathbf{x})$为$KAN_i$的差分矩阵:
$$
S(\mathbf{x}) = F_{agg} (F_{score}(\Delta^1(\mathbf{x})), \dots, F_{score}(\Delta^P(\mathbf{x})),)
$$
$F_{agg}$ 是一个合适的聚合函数,如最大值函数。由于分区是不重叠的,对于InD样本,将**只有一个模型将样本识别为InD(高InD分数)**,而其余的模型均将其标记为OOD(低InD分数)。

实验
对于图像中的OOD检测,实验设置遵循OpenOOD (Yang et al., 2022)基准协议。
考虑的OpenOOD基准使用预训练的ResNet骨干(He等人,2015)进行特征提取
我们利用预先训练的骨干的多个潜在层的信息。如Liu等人(2024a)所示,这种多层集成丰富了特征表示,从而提高了检测精度。具体来说,作者声称最后一层主要包含语义信息,而包括更靠近输入的层允许检测器捕获协变量信息。
结果
仍然使用常用的CIFAR-10和CIFAR-100作为训练ID样本,这里报告的是AUROC,附录中有FPR95的结果,但效果上没有太大区别