多意图识别任务
引言——多任务学习
多意图识别介绍:
上一个实验是对单意图进行分类,即单意图识别任务。不过现实情况是很多SLU情况是多意图的,那么有两个问题需要解决:
- 有多少个意图?
- 这些意图分别是什么?

对于这个两个问题,有如下处理方法:
- 设置一个阈值:大于某个阈值判断属于该类
- 先判断有多少类(比如K类),最终取Top K
但是阈值不是很好设置,因为我们不知道测试集。因此使用第二种方法,对两个任务进行学习。
因此引入多任务学习概念 #多任务学习
多任务学习
多任务学习通过同时学习多个相关任务来提高模型的性能和泛化能力。其核心思想是利用任务之间的共享信息,使得每个任务都能从其他任务中获益,从而提升整体学习效果。
其核心思想是:
- 共享表示:多个任务共享一部分模型参数,使得模型能够学习到更通用的特征表示。
- 任务相关性:利用多个相关任务之间的联系,通过共享参数和特征表示,促进任务之间的信息传递和共享。
因此,我们可以把上面两个任务进行联合学习,从而获得更泛化的表现。后面的个人大作业 AGIF 也同理,联合学习意图识别与槽填充任务,获得更好的表现
学习方式
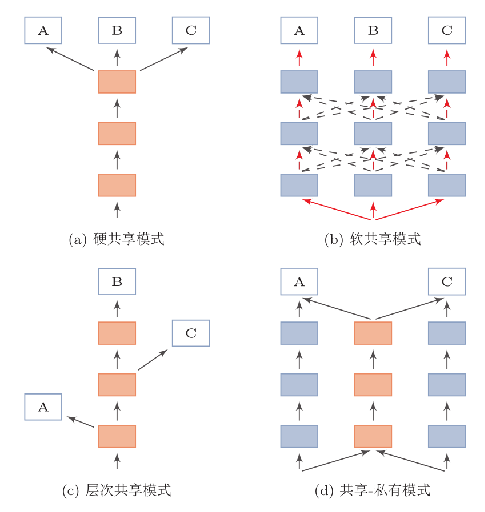
1. 硬共享模式(Hard Sharing)
在硬共享模式中,所有任务共享一个公共的表示层(通常是网络的前几层)。即,任务之间的共享是固定的,所有任务使用相同的参数进行训练。这意味着,不同任务之间的共享是完全一致的,并且不区分哪些层是为特定任务优化的。
- 优点:可以有效利用所有任务之间的相似性,提高训练效率,并减少模型的参数数量。
- 缺点:共享过多可能导致任务间的冲突,尤其是在任务差异较大时,可能无法充分发挥每个任务的特点。
2. 软共享模式(Soft Sharing)
在软共享模式中,模型在任务之间共享某些层的参数,但这种共享是可调的。每个任务可以有一些专用的网络层,同时在某些层共享参数。这意味着模型在某些层共享信息,但在其他层上为每个任务分配独立的参数。
- 优点:允许模型为不同任务调整共享的程度,可以减少任务间的冲突,适应任务的多样性。
- 缺点:相比硬共享,模型结构可能会变得更加复杂,增加了训练过程中的调参难度。
- 本次的任务即为软共享,除了最后一层以外都是共享的参数
3. 层次共享模式(Hierarchical Sharing)
层次共享模式结合了硬共享和软共享的特点。模型在不同的层次上对任务进行不同程度的共享。例如,模型的前几层可能共享,而后面的层可能为不同任务定制。这种方式允许模型在低层次上共享通用特征,在高层次上保持任务特异性。
- 优点:能够更灵活地控制共享的深度,有助于在低层次提取通用特征,在高层次保留任务特定信息。
- 缺点:设计较为复杂,需要仔细选择共享的层次和策略。
4. 共享-私有模式(Shared-Private)
共享-私有模式是多任务学习中的一种混合模式,其中部分网络层是共享的,而其他层则是私有的(任务特定的)。在这种模式下,每个任务不仅共享一些基础的表示层,还拥有专门为任务定制的私有层。私有层通常位于网络的后部,用于处理特定任务的细节。
- 优点:这种模式能够在保证任务之间共享信息的同时,为每个任务保留一些特有的特征,避免任务间冲突,提升模型的表现。
- 缺点:相比硬共享和软共享模式,这种模式会增加更多的参数和计算开销。
task 1 RNN入门
[!question] 根据给定的代码与数据,参考课件内容,填充完整models.py的代码,并比较CNN、LSTM、GRU的性能
CNN的部分比较熟悉了,主要的特点是局部连接、权重共享、汇聚。不过RNN的老是记不住(平时做视觉任务多,所以没怎么做过RNN…),现在再来复习一下之前blog写的:[循环神经网络RNN]
LSTM:输入门、遗忘门、输出门 + 细胞状态
GRU:更新门、重置门 + 隐状态
不过当时写的内容中有段我觉得还挺有趣的,贴在这里再看看:
[!note] Jürgen Schmidhuber老爷子提了一嘴关于梯度消失(Gradient Vanishing)的处理历程:
- Stacking
- ReLU
- LSTM
- highway nets
- residual nets
其中,LSTM和resnet似乎在一定程度上存在关联(ref: 为什么Ilya说LSTM是一个旋转90度的ResNet?)
代码
Pytorch把LSTM和GRU进行了很好地封装,让我们来看看:
1 | class LSTM(nn.Module): |
lstm的输出:
out是LSTM的输出序列。它包含了LSTM在每个时间步的隐状态(hidden state),即每个时间步的输出。- 在默认情况下,当
batch_first=True时,out的形状为(batch_size, sequence_length, hidden_size)。 out[t]即表示了t时间步时的隐状态
- 在默认情况下,当
h_n是LSTM的最终隐状态。它表示LSTM在所有时间步之后,最终时刻的隐状态。h_n是LSTM在最后一个时间步(通常是序列的最后一个时间步)产生的隐状态。h_n的形状为(num_layers * num_directions, batch_size, hidden_size)- 由于我们设置了双向LSTM,因此
num_directions = 2,所以h_last = torch.cat((h_n[-2], h_n[-1]), dim=1)实际上等价于h_last = torch.cat((h_n[0], h_n[1]), dim=1)
c_n是LSTM的细胞状态(cell state)。LSTM使用一个特殊的状态(细胞状态)来存储长期信息,c_n表示的是LSTM在序列结束时的细胞状态。c_n的形状与h_n相同,也是(num_layers * num_directions, batch_size, hidden_size)。
[!example] 假设我们有以下LSTM参数:
batch_size= 3sequence_length= 5hidden_size= 4num_layers= 1num_directions= 1(单向LSTM)
那么:
out的形状是(3, 5, 4),表示每个时间步(5个时间步)和每个样本(3个样本)的隐状态输出。h_n的形状是(1, 3, 4),表示LSTM在最后一个时间步的隐状态(1层,3个样本,4个特征维度)。c_n的形状是(1, 3, 4),表示LSTM在最后一个时间步的细胞状态。
GRU的代码与LSTM基本一致,只需要替换模块即可,此处不进行叙述
为什么取最后一步:
- 对于意图识别任务,我们需要看完整个sequence才知道代表的是什么意图
- 为了提高准确率,我们同时使用双向lstm,来更好地存储记忆信息
- 对应的需要把两个方向的输出进行拼接,然后再接到线性头
为什么要设置batch_first
[!question] 为什么LSTM和GRU不需要设置premute?
与batch_first有关
在PyTorch中,batch_first 是一个与 RNN、LSTM 和 GRU 等循环神经网络模块相关的参数。它用于指定输入和输出数据的维度顺序,特别是数据的 批量大小(batch size)、时间步(time steps) 和 特征维度(feature dimension) 的排列方式。
作用
在默认情况下,PyTorch中的RNN、LSTM和GRU模块期望输入数据的形状为 (sequence_length, batch_size, input_size),其中:
sequence_length是序列的长度(时间步的数量),batch_size是批量的大小,input_size是每个时间步的输入特征的维度。
但在很多情况下,用户可能希望批量的大小 batch_size 在前面(这样可以直接把embedding塞进去),这样每个时间步的特征在后面,这种情况可以通过设置 batch_first=True 来实现。
使用 batch_first=True
当将 batch_first=True 时,输入和输出的形状将被转换为 (batch_size, sequence_length, input_size),即:
batch_size是批量的大小,sequence_length是序列的长度(时间步的数量),input_size是每个时间步的输入特征的维度。
这样更符合许多深度学习框架中的常规数据格式,也使得数据操作更直观,尤其是在处理与批量相关的操作时。
举例说明
假设你有一个批量大小为 B=3 的输入数据,序列长度为 T=5,每个时间步的特征维度为 F=4。
- 当
batch_first=False时(默认设置): 输入数据的形状应该是(sequence_length, batch_size, input_size),即(5, 3, 4)。 - 当
batch_first=True时: 输入数据的形状应该是(batch_size, sequence_length, input_size),即(3, 5, 4)。
例子
假设我们有一个批量大小为3,序列长度为5,每个时间步的输入特征维度为4的RNN输入。示例如下:
1 | import torch |
总结
batch_first是用于指定输入和输出的维度顺序。batch_first=True时,数据的形状为(batch_size, sequence_length, input_size),即批量大小在前。- **
batch_first=False**(默认设置)时,数据的形状为(sequence_length, batch_size, input_size),即序列长度在前。
选择 batch_first=True 可以让数据的顺序更符合某些场景的需求,特别是在数据处理和操作时可能更加直观。
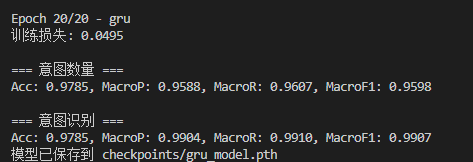
实验结果
CNN: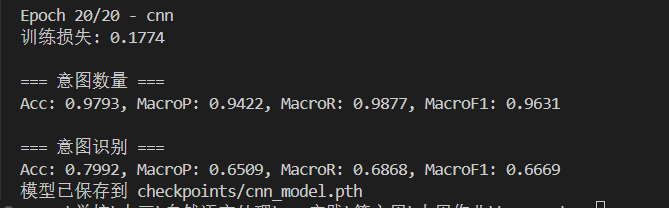
GRU: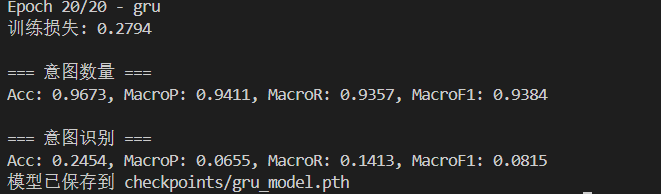
LSTM: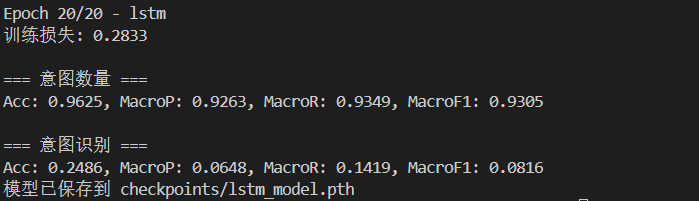
会发现在相同的参数下,GRU和LSTM的意图识别效果并不好,我们需要进行超参数搜索。
task 2: 超参数搜索
[!question] 根据验证集调参,使得lstm与gru模型在测试集的macro-f1分数尽量在95以上
代码位于grid_search.py,为了减少运算时间,这里只对以下超参数进行网格搜索:
1 | batch_size_list = [32, 64] |
同样的,在验证集上进行最优超参数搜索,保留最优模型,再加载模型对测试集上测试。
需要注意:
- 每次搜索要重新对DataLoader和model进行初始化
- 记得修改数据集为test数据集
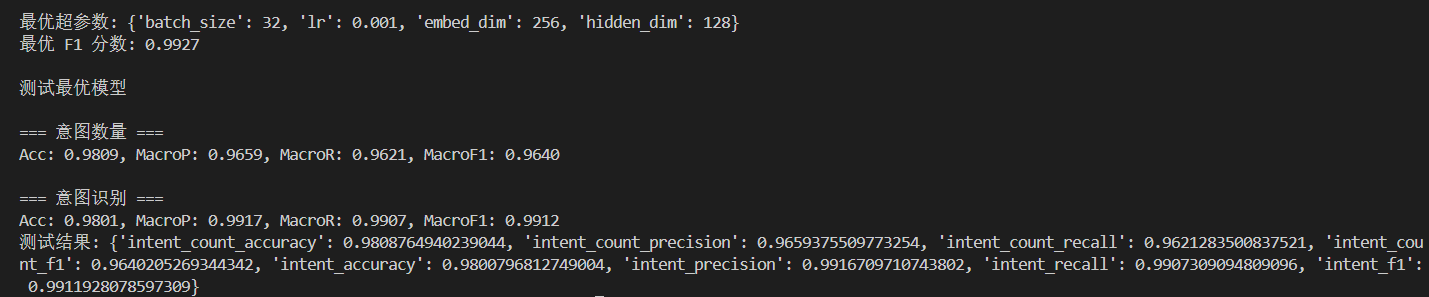
LSTM结果
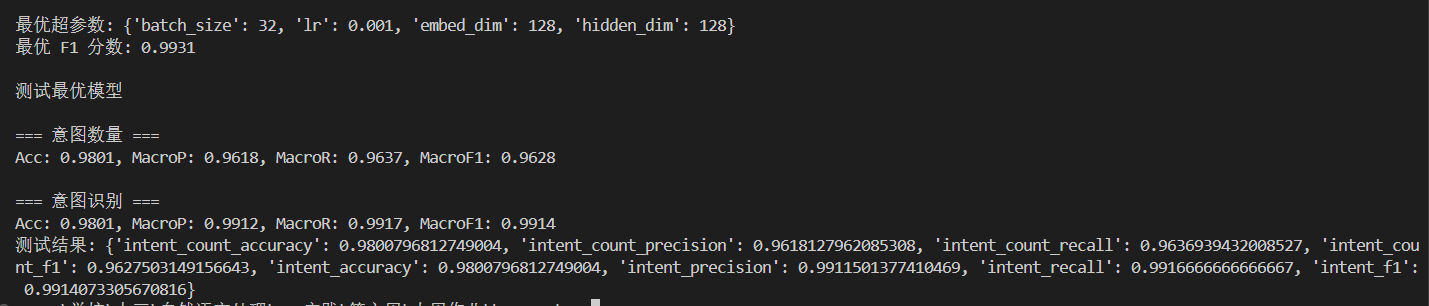
GRU结果
总结
实际上,对于RNN类模型,学习率设置在 1e-3 范围效果会好一些
task 3: 代码观察
前几个py文件并没有太大区别,但是trainer.py需要重新梳理,让我们来看一下是怎么进行两个任务联合学习的:
1 | # trainer.py |
注意:
- 训练部分:
loss_ic = intent_count_loss_fn(ic_logits, intent_counts - 1),这里需要将真实的counts-1后再做交叉熵intent_counts表示每个样本的意图数量。通常,这个值是 从1开始的(即 1-based indexing),也就是说,intent_counts[i]可能表示该样本包含 1 个、2 个、3 个意图,依此类推。- **模型的输出
ic_logits**,例如ic_logits[i],表示 预测的意图数量。但是,在大多数机器学习框架中,通常期望 分类任务的标签是从0开始的(即 0-based indexing)。因此,如果模型预测的类别是从0开始的,真实标签也应该是从0开始的。因此需要减去1
- 计算损失用
loss = loss_ic + loss_it进行计算联合损失
- 验证部分:
ic_preds_batch = torch.argmax(ic_logits, dim=1).cpu().numpy()需要用argmax找到最大值对应的索引(0和1)- 对应的
ic_true_batch = (intent_counts.cpu().numpy() - 1),同样需要 -1 来对齐类别数 it_logits维度是[batch_size, intent_nums],与it_labels一样- 为了将
it_logit的概率向量转为对应类别预测,需要进行一定处理,将前ic_preds_batch[i]+1大的标记为1,其余标记为0 - 最后再使用
precision_recall_fscore_support进行计算指标
[!question] 细心的话会发现,貌似两个任务的矩阵维数是不一样的,但是调用了同一个函数进行指标计算,这是为什么呢?
precision_recall_fscore_support 函数使用
precision_recall_fscore_support 函数是用来计算分类任务中的精度(Precision)、召回率(Recall)、F1值(F1-Score)等指标的函数,通常用于 多分类问题 或 多标签分类问题。尽管 intent_count_true 和 intent_count_preds 是一维数组,而 it_true_np 和 it_pred_np 是二维数组,它们都可以传递给 precision_recall_fscore_support,这是因为该函数支持多种形式的数据输入,包括 多标签分类任务 和 多类别分类任务。
1. precision_recall_fscore_support 的输入形式
precision_recall_fscore_support 接受两个主要参数:
- 真实标签(true labels):真实的标签数据,可以是
1D或2D数组。 - 预测标签(predicted labels):模型的预测标签,同样可以是
1D或2D数组。
这两者的数据形状应该匹配,因此即便一个是一维数组,另一个是二维数组,只要它们在合适的情境下对齐(即它们的维度是适当的),就可以传递给该函数。
2. 关于 precision_recall_fscore_support 的处理逻辑
- 对于
intent_count_true和intent_count_preds(一维数组): 这两个数组包含的是 单标签分类任务 的信息,表示每个样本的 意图数量预测。这里没有多个标签,只是预测每个样本有多少个意图。因此,这两个数组是1D数组,它们表示每个样本对应的意图数量,precision_recall_fscore_support会基于这些数量进行计算。
例如:
intent_count_true:[1, 2, 0]intent_count_preds:[1, 2, 1]
在这种情况下,precision_recall_fscore_support 将计算 意图数量 预测的 准确率、精度、召回率和F1值。
- 对于
it_true_np和it_pred_np(二维数组): 这两个数组包含的是 多标签分类任务 的信息,表示每个样本的 多个意图的预测。每个样本可以对应多个标签,因此这些数组是2D数组,每个标签对应每个样本的二进制表示(例如,1表示存在该意图,0表示不存在该意图)。
例如:
it_true_np(真实标签):[[1, 0], [1, 1], [0, 1]],表示每个样本对应的真实意图(第一个样本有意图0,第二个样本有意图0和1,第三个样本有意图1)。it_pred_np(预测标签):[[1, 0], [0, 1], [1, 1]],表示每个样本的预测意图。
在这种情况下,precision_recall_fscore_support 会计算 多个意图的精度、召回率和F1值,同时使用宏平均(macro)来处理多个标签。
3. 总结为什么可以一起使用
intent_count_true和intent_count_preds是一维数组,它们被用于 意图数量预测,这通常是一个 回归 问题(虽然它实际上是分类问题),因此可以直接传递给precision_recall_fscore_support来计算 精度、召回率、F1值 等度量。it_true_np和it_pred_np是二维数组,代表 多标签分类问题,每个样本有多个标签,且每个标签可以是0或1,表示是否预测到该意图。这些数据也可以直接传递给precision_recall_fscore_support来计算多标签的精度、召回率和F1值。
核心点:
precision_recall_fscore_support可以处理 多标签分类任务 和 单标签分类任务,它通过检查输入的标签格式来决定如何计算指标。- 对于 单标签任务(如意图数量预测),传入一维数组即可。
- 对于 多标签任务(如多个意图的预测),传入二维数组即可。
函数内部会根据输入的维度进行相应的处理,无论是单标签的分类任务还是多标签的分类任务,它都会返回 精度、召回率、F1值 等指标。
task 4: 损失函数区别
[!question] 请将代码中的nn.CrossEntropyLoss()与nn.BCEWithLogitsLoss()分别改成softmax+NLLLoss与sigmoid+BCELoss的形式,并仔细研究二者的接口区别
官方文档链接:
Softmax — PyTorch 2.6 documentation
CrossEntropyLoss — PyTorch 2.6 documentation
LogSoftmax — PyTorch 2.6 documentation
NLLLoss — PyTorch 2.6 documentation
BCEWithLogitsLoss — PyTorch 2.6 documentation
实际上,我们在训练的时候就可以初见端倪:
1 | intent_count_loss_fn = nn.CrossEntropyLoss() |
注意,ic_logits的维度是 [batch_size, max_intents],intent_counts 的维度是 [batch_size]。it_logits 的维度是 [batch_size, intent_nums],intent_labels 的维度是 [batch_size, intent_nums]
[!question] 怎么
ic_logits和intent_counts的维度不一样?
来看看官方文档:
交叉熵 CrossEntropyLoss
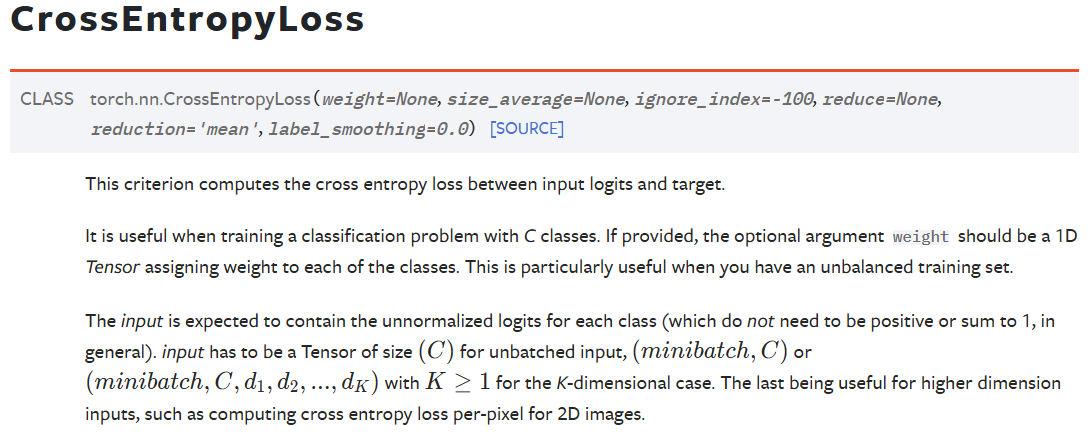

Input(模型输入):
- 可以是形状为:
(C):一个样本的 logits,共C类。(N, C):N个样本,每个样本有C个类。(N, C, d1, d2, ..., dK):更高维度,比如图像,每个像素点都有分类,这种情况下每个位置也预测C个类(每个像素为一个样本)。
- logits 不需要经过 softmax,因为
CrossEntropyLoss会在内部处理 softmax。target: - 形状为
[batch_size],即每个样本的真实标签,通常是一个整数值,表示真实类别的索引(从0开始)。例如,若一个样本属于类别 2,则target的值是 2。 - 也有更高维度的标签
(N, d1, d2, ..., dK)(如图像每个像素有标签)
实际上,正如官方文档所说,它可以等价为应用 LogSoftmax 在 input 上,然后和 target 做NLLLoss
BCEWithLogitLoss
BCELoss(Binery Cross-Entropy Loss): 对每个类别都做二分类任务
BCEWithLogitsLoss = Sigmoid + BCELoss
BCEWithLogitsLoss 是一种结合了 Sigmoid 层 和 Binary Cross Entropy(BCE)损失 的损失函数,通常用于 多标签分类问题。它的特点是:在计算 二元交叉熵损失 时,不需要额外的 Sigmoid 激活函数,内部已经包含了 Sigmoid 操作,从而提高了数值稳定性。
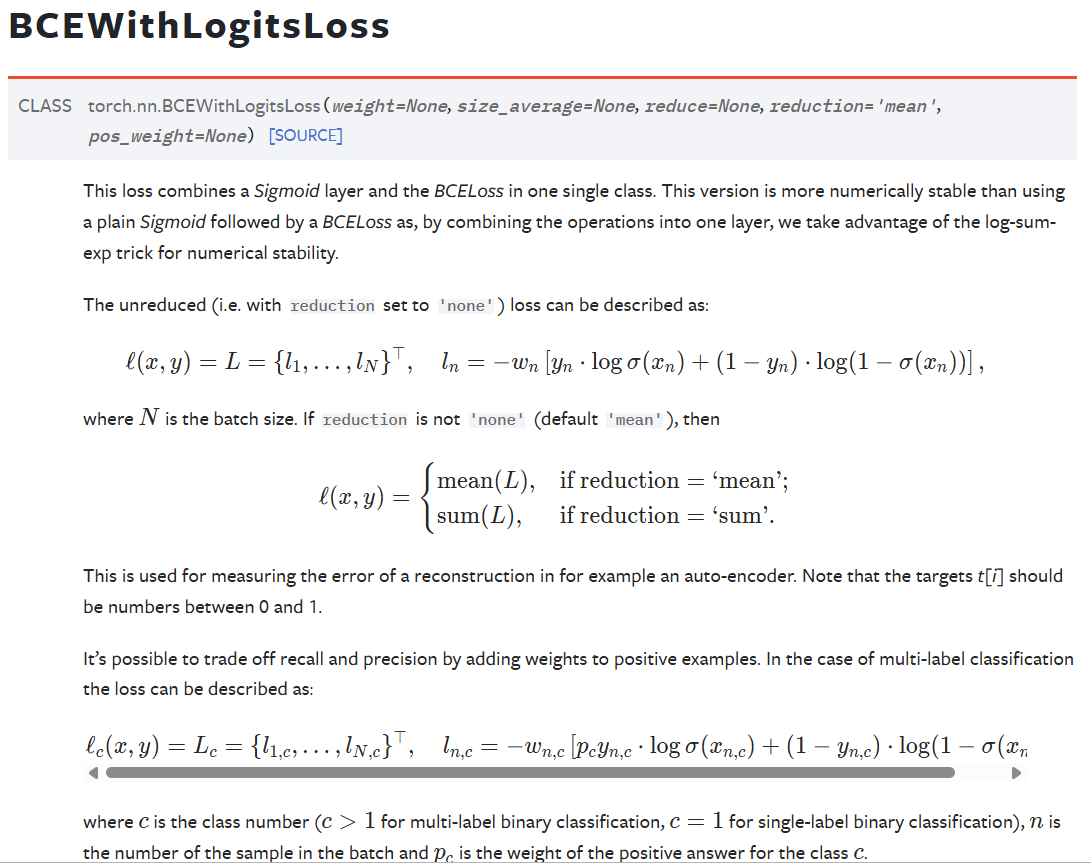
1. BCEWithLogitsLoss 的原理
这个损失函数的设计理念是:
- Sigmoid 将 logits(未经缩放的模型输出)转换为 [0, 1] 范围内的概率值。
- BCELoss 则用来计算这些概率值和真实标签(目标标签)之间的二元交叉熵损失。
2. 公式
BCEWithLogitsLoss 损失可以通过以下公式描述:
$$\ell(x, y) = -\left[ y_n \log(\sigma(x_n)) + (1 - y_n) \log(1 - \sigma(x_n)) \right]$$
其中:
- $x_n$ 是第 $n$ 个样本的预测 logits(未经 Sigmoid 激活的原始输出)。
- $y_n$ 是第 $n$ 个样本的真实标签,通常是 0 或 1。
- $\sigma(x_n)$ 是对 $x_n$ 进行 Sigmoid 激活后的结果,表示为 $\frac{1}{1 + \exp(-x_n)}$,即输出的是每个标签为 1 的概率。
计算方式:
- 对于每个样本 $n$,损失函数会先对其预测的 logits 进行 Sigmoid 转换,得到该样本每个标签为 1 的概率(范围在 0 和 1 之间)。
- 然后,基于这个概率和真实标签 $y_n$,计算二元交叉熵损失(即两个概率分布之间的差距)。
3. Reduction 参数
- **
reduction**:指定如何计算损失的平均值或总和:'none':返回每个样本的损失值(没有聚合,返回大小为batch_size的损失张量)。'mean'(默认):返回损失的平均值。'sum':返回所有样本损失的总和。
4. 损失函数的作用和应用
- BCEWithLogitsLoss 主要用于 多标签分类 和 回归问题,尤其适用于每个样本有多个标签的情况,例如:
- 预测一个文本样本是否包含某个特定标签(如情感分类任务中判断文本是否为“积极”、“消极”等)。
- 用于 autoencoder 的重构误差计算,每个输出值都代表一个标签的存在概率。
5. 与传统的 BCELoss 比较
- 通常情况下,你需要先对
logits应用 Sigmoid 激活函数,再使用 BCELoss 来计算损失。而 BCEWithLogitsLoss 将 Sigmoid 和 BCELoss 整合成一个单一的函数,这样计算上更加高效和数值稳定。 - 数值稳定性:计算交叉熵时,尤其是当预测概率非常接近 0 或 1 时,直接应用 log 函数可能会导致 数值溢出(例如,如果预测值接近 0 或 1,log(0) 会导致负无穷)。但
BCEWithLogitsLoss内部使用了 log-sum-exp trick 来避免这种情况,从而提高了稳定性。
6. 使用场景
- 多标签分类问题:每个样本可以有多个标签,不同标签之间不需要互斥。
- 回归问题:当目标值是 0 或 1 之间的概率时,也可以使用 BCEWithLogitsLoss 来计算误差。
总结
BCEWithLogitsLoss是一个结合了 Sigmoid 和 BCELoss 的损失函数,专门用于处理多标签分类任务或二元分类问题。- 它的输入是 未经过 Sigmoid 的 logits,且自动执行 Sigmoid 和 BCELoss 的计算,保证了数值的稳定性。
reduction参数允许你选择损失计算的方式:返回每个样本的损失、损失的均值或总和。
里面的shape要求严格与输入一致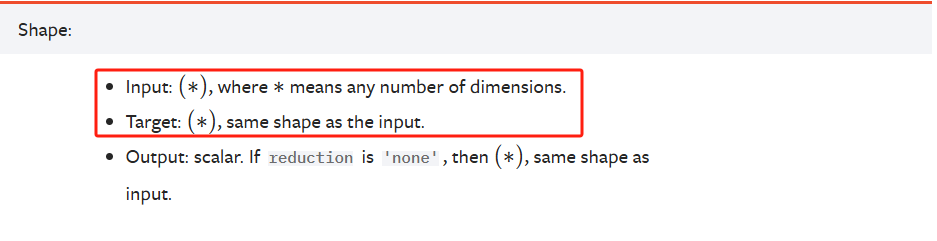
替换
可以自己写两个class替换原本的交叉熵和BCE
1 | # 使用softmax + NLLloss实现CrossEntropyLoss |
训练效果上也没有什么区别,以GRU为例: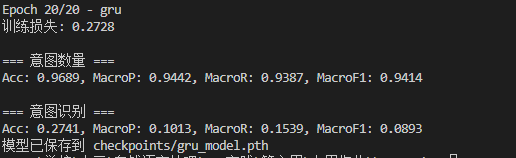
调整为最优超参数后: