文本分类任务
[!info] 任务难度不是很大,关键的问题其实是维度。要始终记得神经网络拟合的只是一个分布,不是一个结果
task 1 序列标注效果评价
序列标注问题介绍
序列标注是一种自然语言处理任务,目标是为序列中的每个元素分配一个标签。
应用领域:自然语言处理(NLP):如分词、命名实体识别、情感分析。
生物信息学:基因序列的标注。
其他领域:时间序列数据分析、视频中每帧图像标注等。
常见方法:
- 传统方法:
- 隐马尔可夫模型(HMM)
- 条件随机场(CRF)
- 基于深度学习的方法:
- 循环神经网络(RNN)
- 长短时记忆网络(LSTM)
- 双向LSTM(BiLSTM)+ CRF 等
- Transformer
任务介绍
[!question] 根据给定的代码与数据,参考课件内容,填充完整models.py的代码,并比较CNN、LSTM、GRU的在序列标注任务的性能
比上周的任务多了一个插槽填充。需要注意的是,槽填充需要对每个位置都进行槽位预测,因此我们需要有同样长的经过神经网络处理后的序列作为输入,才能得到对应每个位置的槽位
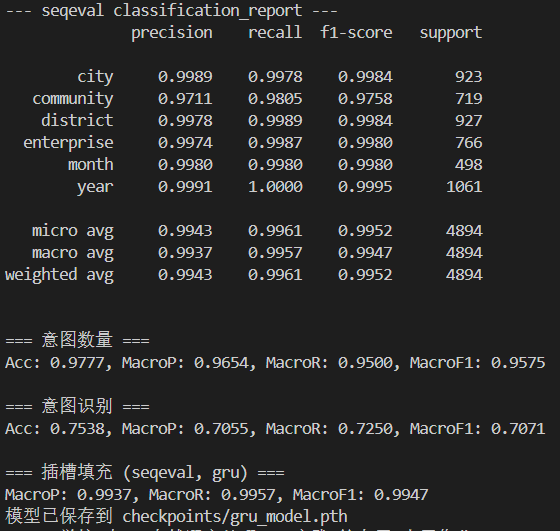
CNN
1 | class CNN(nn.Module): |
对于槽填充任务,我们需要padding来帮我们保持序列长度一致。经过卷积后,我们还需要把维度进行调整,因为线性层处理的是最后一个维度,但我们需要保持序列长度一致,不能对seq_len处理,只能对embed_dim处理,把它再映射回原本的 num_slot_labels
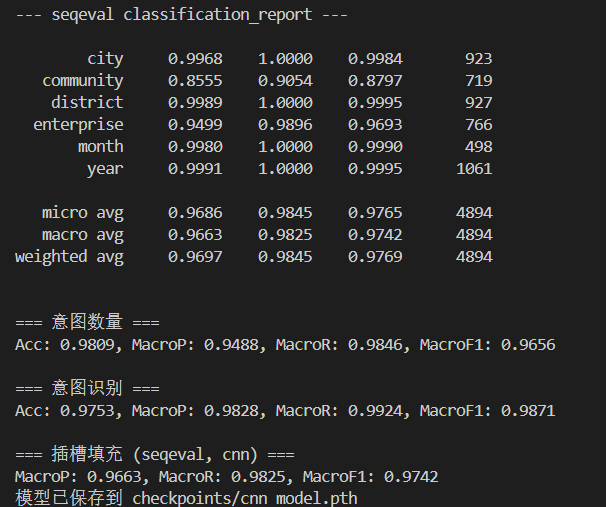
LSTM
1 | class LSTM(nn.Module): |
对于意图识别任务,同样可以传入最后一个隐状态。
但是对于槽填充任务,需要将整个lstm的输出作为输入,然后通过线性头得到对应的slot_label
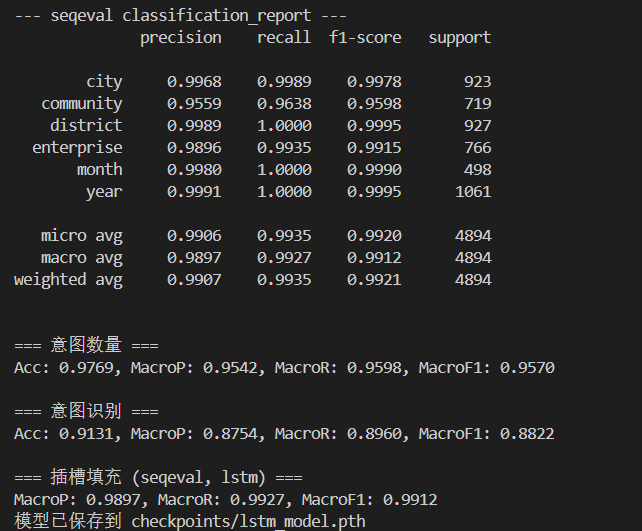
GRU
内容类似,在此不再阐述(不过在此超参下训练效果不是很好,上周优化时发现,学习率调到1e-3会好很多,不过这周的重点是比较不同的训练方式和方法)
task2 联合训练与分别训练效果对比
[!question] 比较意图识别与插槽填充任务单独训练与执行(即单独训练意图识别/插槽填充并推理)与联合训练(即多任务学习)时不同模型性能的比较
代码
原本的训练代码(整体结构没有太大变化,因此不对代码进行详细阐述):
1 | intent_count_loss_fn = nn.CrossEntropyLoss() |
在NLP任务中,由于需要保持输入序列长度的一致性,通常会将其填充至相同的长度,填充的部分通常用一个特殊的标签(如 -100)表示。通过设置 ignore_index=-100,这些填充标签就不会影响损失的计算和模型的训练。
在 PyTorch 的 nn.CrossEntropyLoss 中,ignore_index 是一个参数,用于指定在计算损失时需要忽略的目标标签的值。具体来说,当目标标签的值等于 ignore_index 时,这个标签对应的损失将不会被计算,也不会对梯度产生影响。
在目前的loss计算中,可以看到 loss = loss_ic + loss_it + loss_sl,意图识别和槽填充是进行联合训练的,我们需要将其变为单独训练。我的做法比较简单,把原本的函数拆成两个任务函数,然后在训练过程中分别调用即可:
1 | def train_epoch_intent(model, loader, optimizer, intent_count_loss_fn, intent_loss_fn, slot_loss_fn, device): |
CNN
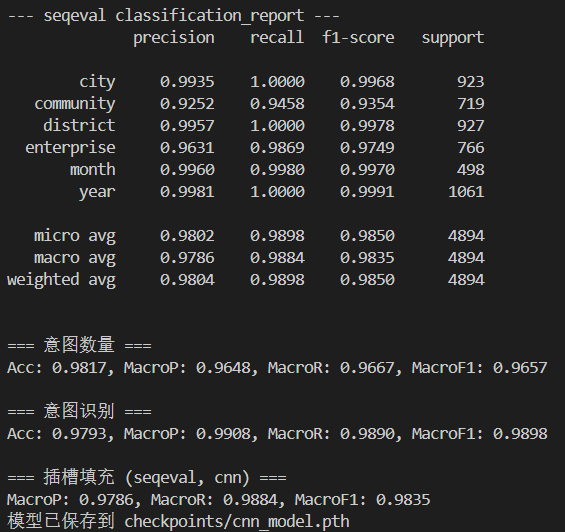
跟联合训练差别不大
LSTM
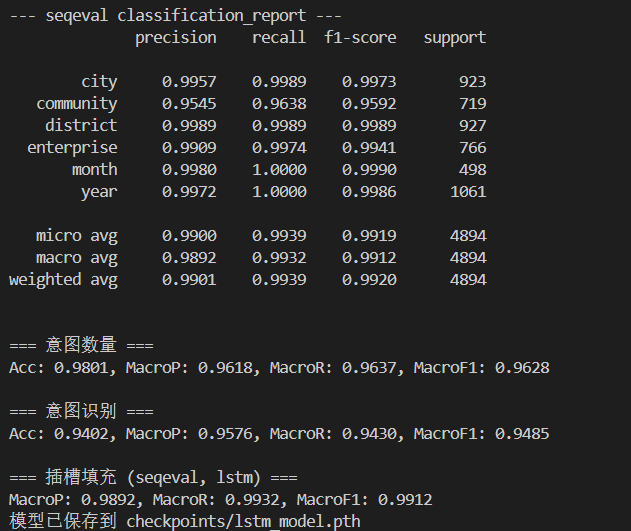
意图识别的结果明显比联合训练的好,在GRU上也可看到
GRU
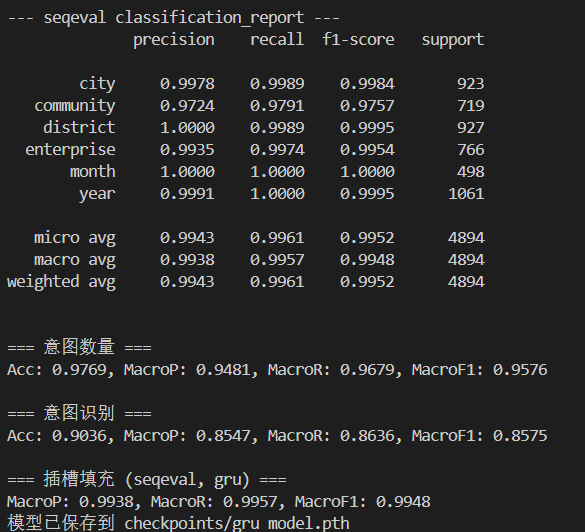
同样效果比先前联合训练好。
总结
跟课上提到的一样,多任务联合学习虽然可以提高泛化能力,但是训练的难度更大,同时需要更大的数据集。如果不做特殊处理(调整超参等),效果可能没有分别训练好。
在训练过程中也可以看到,联合训练时,loss一直都比较高,对于意图识别会有明显的影响。怎么更好地解决这个问题,task3给出了一些思路。
task3 论文复现
[!question] 复现《A RESULT BASED PORTABLE FRAMEWORK FOR SPOKEN LANGUAGE UNDERSTANDING》中关于RBFN的部分
关于此论文的具体叙述在后面。由于只需要复现RBFN部分,因此对于历史嵌入向量我们直接用embedding进行代替。backbone使用LSTM。
代码量不大,主要是思考公式与代码之间是怎么进行衔接的,麻烦的地方在于矩阵维数的处理。
其实这也相当于做了一个简单的消融实验,就是比较有没有这个结构对结果带来的影响
代码
1 | class SLU(nn.Module): |
维度分析
lsvI.unsqueeze(1).expand(-1, embed.size(1), -1):lsvI的维度是[batch_size, hidden_dim]。unsqueeze(1)会把lsvI的维度变成[batch_size, 1, hidden_dim]。expand(-1, embed.size(1), -1)会把第二维扩展到seq_len,即[batch_size, seq_len, hidden_dim]。
embed:embed的维度是[batch_size, seq_len, embed_dim]。
torch.cat(..., dim=-1):- 将扩展后的
lsvI(维度[batch_size, seq_len, hidden_dim])和embed(维度[batch_size, seq_len, embed_dim])沿最后一维(dim=-1)拼接。 - 拼接后的维度是
[batch_size, seq_len, hidden_dim + embed_dim]。
- 将扩展后的
所以,拼接后的张量的维度是 [batch_size, seq_len, hidden_dim + embed_dim],然后通过 self.new_intent 或 self.new_slot 进行线性变换,再转换成embed_dim
实验结果
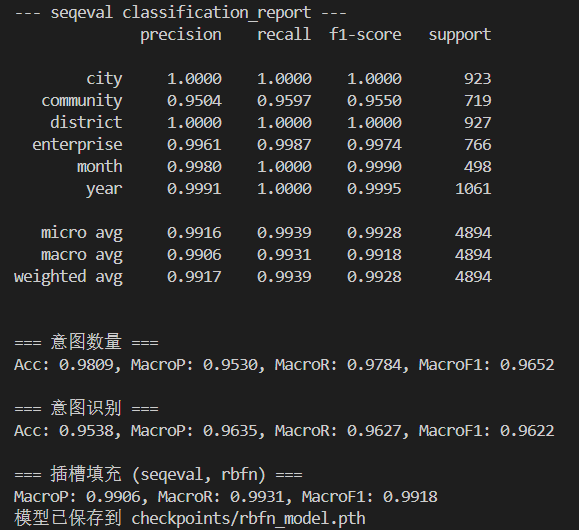
使用LSTM作为backbone,很明显看到,相比于先前的联合训练和分别训练,意图识别的F1分数均有了明显提高,一方面证明了意图识别与槽填充这两个任务的相关性,另一方面是这个结果反馈网络的有效性。
论文:A RESULT BASED PORTABLE FRAMEWORK FOR SPOKEN LANGUAGE UNDERSTANDING
AAAI 2025
Author: Lizhi Cheng, Wenmian Yang, Weijia Jia
问题背景
现有的多轮口语理解(SLU)方法存在以下问题:
- 移植性差:现有方法的基础模型与多轮模块耦合紧密,难以直接替换为最新的单轮SLU模型。
- 信息利用不足:仅利用历史对话的原始文本,忽略了历史预测结果(如意图和槽位标签)的语义信息。
- 任务间交互缺失:意图检测(ID)和槽位填充(SF)的预测结果未充分交互,导致错误传递或冗余。
为解决上述问题,本文提出了一种基于结果的可移植的SLU框架(RPFSLU)
RPFSLU允许大多数现有的单轮SLU模型从多轮对话中获取上下文信息,并在预测过程中充分利用预测结果。在RPFSLU中,现有的单匝SLU模型(即基本模型)是一个只需要提供预测结果的黑箱。所以没有必要去了解或改变它们的内在结构。
RPFSLU一般由两部分组成,即:对话历史表示(DHR)和基于结果的双反馈网络(RBFN)。
- DHR的目标是从历史话语和历史预测结果中获取上下文信息。
- RBFN的目的是将ID和SF的预测结果融入网络中,并利用结果中包含的语义信息进行更准确的预测。
- 更具体地说,DHR输入当前话语及其对话历史,包括历史话语和预测结果,并输出包含上下文信息的嵌入序列。
- RBFN包含两轮预测过程。在实际应用中,我们首先从基本模型(任意单圈SLU模型)中获取ID和SF的第一轮预测结果,并将结果嵌入到本征状态向量中。然后,将潜在状态向量与话语的单词嵌入进行合并,并将合并后的嵌入重新发送到基本模型中,以预测第二轮结果。最后,我们将两轮的结果合并,并输出最终的SLU结果。
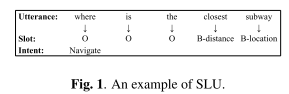
工作内容
Formulation
多回合SLU任务的输入是用户话语序列$U = {u_1, u_2,…, u_n}$,其中$n$表示话语总数。$n = 1$意味着输入没有对话历史。对于任意$u_t∈U$, $u_t = {x_1, x_2,…x_k}$是一个记号序列,其中$k$表示话语$u_t$中tokens的个数。
给定$U$作为输入,我们的任务由两个子任务组成,即ID和SF。ID是一个语义分类任务,用于预测U中每个话语的意图标签; SF是一个序列标记任务,用于给每个话语中的token一个槽标签。
Overview
RPFSLU旨在将现有的单回合SLU模型(即所谓的基本模型)应用于多回合SLU任务,并在预测过程中充分利用预测结果。由于基本模型在RPFSLU中作为黑盒工作,只需要提供预测结果。没有必要去理解或改变它们的内部结构。因此,RPFSLU可以使大多数现有的SLU模型受益
简而言之,RPFSLU由两部分组成:DHR和RBFN。DHR工作在整个网络的最开始,旨在从对话历史中获得话语和预测结果中包含的语义信息,并将这些上下文信息提供给基本模型。RBFN旨在将预测结果中包含的语义信息整合到基本模型中,提高每一次的表现。
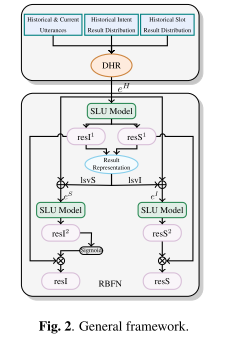
作者提出了一种基于结果的可移植框架(RPFSLU),包含两个核心模块:
- 对话历史表示(DHR):
- 从历史对话的原始文本及其预测结果(ID和SF)中提取语义信息,生成上下文相关的嵌入表示。
- 通过注意力机制加权历史潜在状态向量,并与当前词嵌入融合(公式7-10)。
- 基于结果的双反馈网络(RBFN):
- 进行两轮预测:第一轮生成初步结果,第二轮利用结果的潜在状态向量(公式1-4)优化预测。
- 通过双向反馈(ID结果指导SF,SF结果验证ID)增强任务间交互(公式11-14)。
结果表示机制
在SLU中,预测结果的每个类别都有特定的含义,因此包含了基本的语义信息。为了有效地利用结果的语义,我们设计了一种结果表示机制,旨在通过特定的潜在状态向量来表示预测结果的分布。
具体来说,受[24]的启发,首先使用两个潜在状态矩阵(嵌入层),即$S^I∈R^{d_I×d_i}$和$S^S∈R^{d_S×d_s}$来表达ID和SF结果的潜在状态,其中$d_I$为意图潜在状态维数,$d_S$为槽潜在状态维数。
然后,对于ID,我们将结果分布$resI$与潜在状态矩阵$S^I$结合,得到基于结果的潜在状态向量$lsvI∈R^{d_I}$
$$
lsvI = S^I \cdot resI
$$
对于槽填充结果$s_{j}$也同理,由$resS = {s_{1},\dots,s_{k}}$:
$$
ls_{j} = S^S \cdot s_{j}
$$
此外,由于SF返回的是一组潜在状态向量序列,我们进一步设计了一种注意机制来计算该序列的加权平均,得到一个话语级潜在状态向量$lsvS∈R^{d_S}$,
$$
lsvS = \sum_{j=1}^{k}\alpha_{j}ls_{j}
$$
其中$α_j$为$ls_j$的权值,
$$
\alpha_{j} = \frac{\exp(V_{a} \cdot \tanh(W_{a} \cdot ls_{j} + b_{a}))}{\sum_{p=1}^{k} \exp(V_{a} \cdot \tanh(W_{a} \cdot ls_{p}+ b_{a}))}
$$
其中$W_a∈R^{d_a×d_S}$和$V_a∈R^{1×d_a}$为全连接矩阵。$b_a∈R^{d_a}$是偏置向量,$d_{a}$是注意层的维数。
通过这个过程,我们得到了两个潜在状态向量$lsvI$和$lsvS$,它们包含了来自预测结果的语义信息,有助于后续的预测过程。
Dialogue History Representation
为了记录对话历史,我们使用记忆列表来存储历史话语和预测结果。如图3所示,内存列表最初是空的,并在每次对话之后更新。在T−1轮对话后,我们将T−1轮的话语、预测ID结果和SF结果保存在内存列表$M = (< u_{1}, resI_{1}, resS_{1} >,…, < u_{T−1},resI_{T−1},resS_{T−1} >)$。
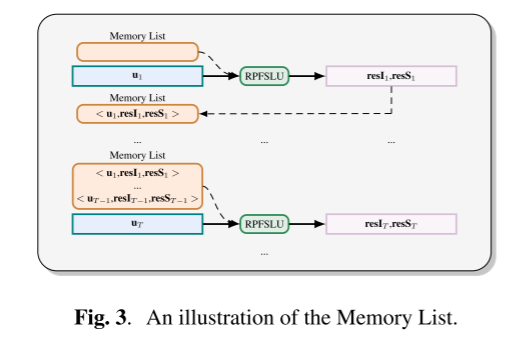
在第t轮对话中,我们首先通过结果表示机制将所有历史结果映射到潜在空间中,得到历史潜在状态向量(latent state vector):
- ID: $LSVI = {lsvI_{1},…, lsvI_{T−1}}$
- SF: $LSVS = {lsvS_{1},…, lsvS_{T−1}}$。
同时,对于从记忆表中取出的每个话语$u_{t}$,我们计算其句子级语义向量$he^t$
$$
e^t = Embedding(u_{t})
$$
$$he_{t} = BiGRU(e^t)$$
实际上,与当前对话语义相似度更高的历史对话应该会产生更大的影响。因此,我们计算每个历史对话的权重$W_h = {w_{1},…, w_{T−1}}$
$$
w_{t} = \frac{\exp(he_{T}^T \cdot he_{t})}{\sum_{j=1}^{T-1} \exp(he_{T}^T \cdot he_{j}) }
$$
然后,我们计算历史ID和SF结果的加权潜在状态向量
$$
lsvI_{H} = \sum_{i=1}^{T-1} w_{t} \cdot lsvI_{t}
$$
$$
lsvS_{H} = \sum_{i=1}^{T-1} w_{t} lsvS_{t}
$$
为了将上下文信息整合到基本模型中,我们将历史潜在状态向量与当前词嵌入$e^T = {e^T_{1},…, e^T_{k}}$,得到新的嵌入$e^H = {e^H_{1},…e_{k}^H}$
$$
e_{j}^H = W^H \cdot (e_{j}^T \oplus lsvI_{H} \oplus lsvS_{H}) + b^H
$$
$e^H$包含当前话语信息以及对话历史中的话语、ID和SF信息。最后,我们将$e^H$输入到任意合适的SLU模型中,得到当前话语的预测结果。
基于结果的双向反馈网络 RBFN
在本节中,我们将详细介绍RBFN,它将预测结果中的语义信息整合到基本模型中,从而获得更全面的预测结果。在实践中,RBFN包含三个步骤。首先,RBFN接收来自DHR的词嵌入序列$e^H$。RBFN利用$e^H$,利用基本模型实现第一轮ID结果分布$resI1$和第一轮SF结果分布$resS^1 = {s^1_{1},…, s^1_{k}}$。
如前所述,在SLU中,ID的预测结果会影响SF的标注,而SF的结果可以验证ID的预测(所谓的Bi-Feedback)。受此启发,在RBFN的第二步,我们通过结果表示机制获得了第一轮结果$lsvI$和$lsvS$的潜在状态向量。然后将潜在状态向量$lsvI$和$lsvS$分别与词嵌入$e^H$合并进行第二轮预测或验证。
具体而言,对于ID结果信息,我们首先将$lsvI$与话语词嵌入$e^H$合并,得到基于ID结果的嵌入序列$e^I = {e^I_{1},…, e^I_{k}∈R^{d_w}}$
$$
e^I_{j}=W^I \cdot(lsvI \oplus e^H_{j}) + b^I
$$
其中$⊕$为拼接操作,$W^I ∈ R^{d_{w} \times (d_w+d_I)}$为全连通矩阵,$b^I ∈ R^{d_w}$为偏置向量。
与ID类似,对于SF结果的信息,我们也将$lsvS$与话语词嵌入$e^H$合并,得到基于SF结果的嵌入序列$eS = {e^S_{1},\dots,e^S_{k}∈R^d_{w}}$
$$
e^S_{j}=W^S \cdot(lsvS \oplus e^H_{j}) + b^S
$$
其中$W^S∈r^{d_w \times (d_{w}+d_{S})}$为全连通矩阵,$b^S∈R^{d_w}$为偏置向量。
随后,我们再次使用基本模型进行第二轮预测。为了利用意图信息指导SF过程,我们将 $e^I$ 重新发送到基本模型中,得到第二轮SF结果$resS^2 = {s^2_{1},\dots, s^2_{k}}$。为了利用槽位信息验证ID预测,我们将 $e^S$ 重新发送到基本模型中以获得第二轮ID结果$resI^2$。特别是,由于$resI^2$的目的是验证$resI^1$,所以在从基本模型输出$resI^2$时,我们将softmax函数替换为sigmoid函数。
在获得两轮结果后,我们将它们合并并计算最终的ID结果$resI$和SF结果$resS$
$$
resI = resI^1 \otimes resI^2
$$
$$
resS = resS^1 \otimes resS^2
$$
最后通过$f(x) = x_i/\sum x_j$对$resI$和$resS$进行归一化
实验
- 为了评估RPFSLU的有效性,在多回合数据集KVRET[25]上进行了实验。
- 数据集由3031个多回合对话组成,其中2425个对话在训练集中,302个在验证集中,304个在测试集中。
- 我们利用验证集来选择超参数,并在测试集上使用我们的框架评估基线模型。
- 对于每个模型,我们都进行了50次实验,并选择了最佳结果。
- 在训练过程中,我们将基本模型中使用的所有超参数(例如批大小,epoch,优化器,学习率等)设置为原始论文。对于RPFSLU中使用的超参数,我们将意图嵌入大小dI设置为8,将槽嵌入大小dS设置为32,将词嵌入大小dw设置为与基本模型相同。注意层数据的维数设置为64。
实验结果
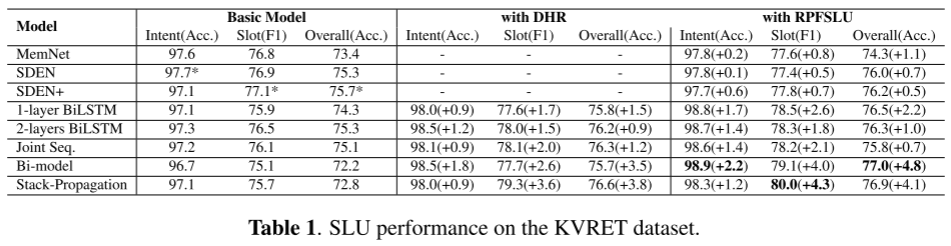
在公开数据集KVRET上的实验表明:
- 性能提升:
- 所有单轮SLU模型(如BiLSTM、Stack-Propagation)结合RPFSLU后,ID准确率、SF F1值和整体准确率均显著提升。
- 例如,Stack-Propagation的SF F1值提升4.3%,Bi-model的整体准确率提升4.8%。
- 模块有效性(消融实验):
- DHR单独使用即可提升模型性能(如1-layer BiLSTM的SF F1值提升1.7%)。
- RBFN通过两轮预测和双向反馈进一步优化结果。
- 兼容性:
- RPFSLU框架无需修改单轮模型的内部结构,支持多种模型(如BiLSTM、Slot-gated等)。
总结
RPFSLU通过灵活利用历史预测结果和任务间交互,解决了多轮SLU的移植性和信息利用问题,显著提升了现有模型的性能。其核心创新在于将预测结果的语义信息显式建模,并通过双向反馈机制实现任务协同优化。