[!question] 根据给定的代码与数据,参考课件内容,填充完整models.py的代码,比较Transformer,Bert,冻结参数的Bert的性能
先介绍两个参数
数据预处理时,增加了两个参数,让我们来看看:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| def encode_data(data, tokenizer, intents_num, slots_num, max_len=128):
input_ids = []
attention_masks = []
token_type_ids = []
intent_labels = []
intent_counts = []
slot_labels = []
for item in data:
tokens = item['tokens']
slots = item['slots']
intents = item['intents']
intent_count = item['intent_count']
encoding = tokenizer(
tokens,
is_split_into_words=True,
padding='max_length',
truncation=True,
max_length=max_len,
return_offsets_mapping=True,
return_tensors='pt'
)
input_ids.append(encoding['input_ids'][0])
attention_masks.append(encoding['attention_mask'][0])
token_type_ids.append(encoding['token_type_ids'][0] if 'token_type_ids' in encoding else torch.zeros_like(encoding['input_ids'][0]))
intent_label = [0] * len(intents_num)
for intent in intents:
intent_id = intents_num.get(intent, -1)
if intent_id != -1:
intent_label[intent_id] = 1
intent_labels.append(torch.tensor(intent_label, dtype=torch.float))
intent_counts.append(torch.tensor(intent_count, dtype=torch.long))
labels = []
word_ids = encoding.word_ids(batch_index=0)
previous_word_idx = None
for word_idx in word_ids:
if word_idx is None:
labels.append(-100)
elif word_idx != previous_word_idx:
if word_idx < len(slots):
labels.append(slots_num.get(slots[word_idx], slots_num['O']))
else:
labels.append(slots_num['O'])
else:
labels.append(-100)
previous_word_idx = word_idx
slot_labels.append(torch.tensor(labels, dtype=torch.long))
return {
'input_ids': torch.stack(input_ids),
'attention_mask': torch.stack(attention_masks),
'token_type_ids': torch.stack(token_type_ids),
'intent_labels': torch.stack(intent_labels),
'intent_counts': torch.stack(intent_counts),
'slot_labels': torch.stack(slot_labels)
}
|
attention_mask
attention_mask 是一个指示哪些token应该被BERT模型“关注”的张量。通常,它用于告知模型哪些部分是实际的输入,哪些部分是填充(padding)部分。attention_mask 的作用是确保BERT模型不会把填充的部分(通常是为了保证输入序列长度一致而添加的无用的token)用于计算注意力机制。
具体含义:
- 值为1:表示对应位置的token是实际的输入,模型应该对该token进行计算。
- 值为0:表示对应位置的token是填充token(padding token),模型应该忽略它,不会对其进行计算。
1
| attention_masks.append(encoding['attention_mask'][0])
|
这行代码从encoding字典中获取生成的attention_mask并将其添加到attention_masks列表。encoding['attention_mask'] 是一个张量,表示输入序列中每个token的有效性,填充token的attention_mask值为0。


token_type_ids
token_type_ids 是BERT模型中用于区分不同句子的标识符,尤其是在处理如问答任务或句对任务时非常重要。BERT模型在输入时通常有两种不同的token类型:一个是表示句子A,另一个是表示句子B。token_type_ids 用于标识每个token所属的句子类别。
- 值为0:表示该token属于第一个句子(句子A)。
- 值为1:表示该token属于第二个句子(句子B)。
1
| token_type_ids.append(encoding['token_type_ids'][0] if 'token_type_ids' in encoding else torch.zeros_like(encoding['input_ids'][0]))
|
这里检查encoding字典中是否包含token_type_ids,如果包含,提取它;如果没有(在某些任务中可能没有这个字段),则生成一个与input_ids相同形状的零张量。
BERT模型通常会将输入的两句话(例如:问题和上下文)作为一对句子对待,每个token会有一个标识符,指示它属于哪个句子。比如:“在2019年5月,广州市荔湾区的力诚欣悦湾与珠江金茂府相比,哪个小区的均价更高?”

由于Bert是Transformer的Encoder架构,因此可以直接拿这个来改。对应有几种方法,一种是使用预训练模型,另一种是重新训练模型
重新预训练模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| class Transformer(nn.Module):
def __init__(self, model_name, num_intent_labels, num_slot_labels, max_intents):
super().__init__()
config = BertConfig(
vocab_size=30522,
hidden_size=128,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=512,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
)
self.encoder = BertModel(config)
self.intent_count_logits = nn.Linear(config.hidden_size, max_intents)
self.intent_classifier = nn.Linear(config.hidden_size, num_intent_labels)
self.slot_classifier = nn.Linear(config.hidden_size, num_slot_labels)
def forward(self, input_ids, attention_mask, token_type_ids):
outputs = self.encoder(input_ids, attention_mask, token_type_ids)
pooled_output = outputs.pooler_output
sequence_output = outputs.last_hidden_state
intent_count_logits = self.intent_count_logits(pooled_output)
intent_logits = self.intent_classifier(pooled_output)
slot_logits = self.slot_classifier(sequence_output)
return intent_count_logits, intent_logits, slot_logits
|
输入数据的处理:self.encoder 接收输入的 input_ids, attention_mask 和 token_type_ids。
- **
input_ids**:表示输入文本的词汇ID的张量。每个ID代表词汇表中的一个词。
- **
attention_mask**:表示哪些词是填充词的张量。0代表填充词,1代表实际输入的词。
- **
token_type_ids**:用于区分不同句子的标识符。在一些任务(如问答任务)中,输入中有两个句子,而BERT需要知道哪个词属于第一个句子,哪个属于第二个句子。
输出:self.encoder 会返回两个主要的输出:
- **
outputs.pooler_output**:pooler_output 是BERT模型的最后一层[CLS] token对应的向量。通常用于分类任务,因为[CLS] token的表示被认为是整个输入序列的聚合表示。这个输出是一个维度为 [batch_size, hidden_size] 的张量。
- **
outputs.last_hidden_state**:last_hidden_state 是BERT模型的最后一层每个token的隐藏状态。它是一个维度为 [batch_size, seq_len, hidden_size] 的张量,其中 seq_len 是输入序列的长度。这个输出用于序列标注任务,因为它包含了每个词(token)的表示。
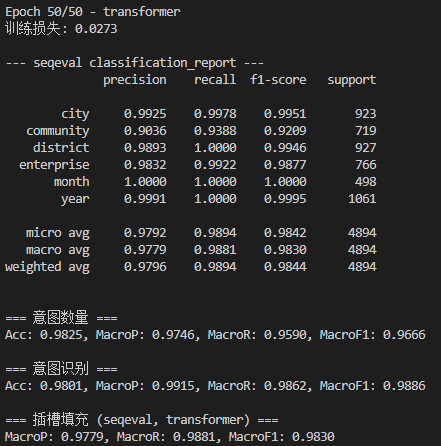
模型微调
也可以加载原本的预训练参数,通过关闭中间层的梯度更新,只更新下游线性头来实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| class BertFreeze(nn.Module):
def __init__(self, model_name, num_intent_labels, num_slot_labels, max_intents):
super().__init__()
self.bert = BertModel.from_pretrained('bert-base-chinese')
hidden_size = self.bert.config.hidden_size
for param in self.bert.parameters():
param.requires_grad = False
self.intent_count_fc = nn.Linear(hidden_size, max_intents)
self.intent_classifier = nn.Linear(hidden_size, num_intent_labels)
self.slot_classifier = nn.Linear(hidden_size, num_slot_labels)
def forward(self, input_ids, attention_mask, token_type_ids):
outputs = self.bert(input_ids, attention_mask, token_type_ids)
pooled_output = outputs.pooler_output
sequence_output = outputs.last_hidden_state
intent_count_logits = self.intent_count_fc(pooled_output)
intent_logits = self.intent_classifier(pooled_output)
slot_logits = self.slot_classifier(sequence_output)
return intent_count_logits, intent_logits, slot_logits
|
param.requires_grad 是 PyTorch 中一个非常重要的属性,通常用于控制模型参数是否需要计算梯度,从而决定它们在反向传播时是否会更新。
在 PyTorch 中,requires_grad 是一个布尔值,表示某个张量是否需要计算梯度。如果 requires_grad=True,那么 PyTorch 会追踪该张量的所有操作,以便在反向传播时计算梯度。如果 requires_grad=False,则 PyTorch 不会为该张量计算梯度,也不会在反向传播中更新它。
效果:
- 冻结模型:冻结BERT模型的参数意味着在训练过程中,BERT的预训练权重将保持不变,只有你自己定义的其他层(如
intent_count_fc、intent_classifier 和 slot_classifier)会参与训练。这种方法通常用于迁移学习,在你只需要对自己特定的任务进行微调时使用。
- 防止过拟合:冻结部分层(特别是像BERT这样的预训练大模型)可以防止模型在小数据集上的过拟合,允许你通过训练较小的部分来保留大模型的特征学习能力。
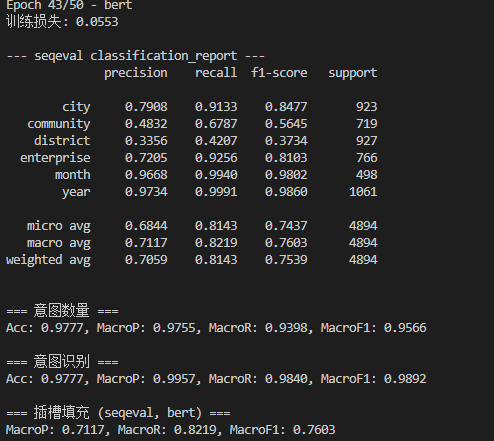
实验结果
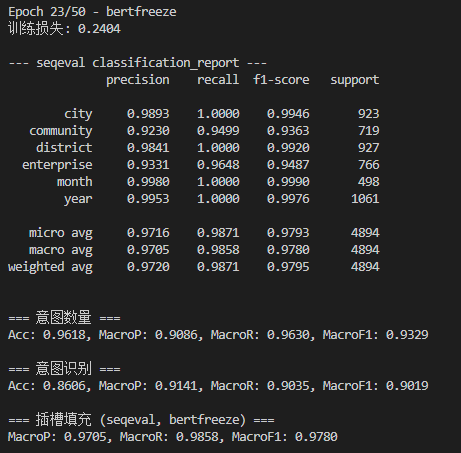
笔记本跑得非常漫长。。这里贴一个23epoch的微调结果:
Pytorch内部集成了Transformer模块,比Bert的封装程度低一些,需要我们自己写入embedding
- BERT模型:BERT已经预训练了一个词嵌入层,因此当你使用BERT时,输入的
input_ids 是直接将单词转换为数字ID的,这些数字ID会传入BERT的嵌入层(Embedding Layer),然后自动映射到一个高维的词向量空间中。因此,BERT本身的输入已经包含了词嵌入的功能,不需要再额外添加一个嵌入层。
- Transformer实现的Bert:你在构建一个自定义的Transformer模型(而不是直接使用BERT),并且从头开始训练模型的词嵌入。所以,必须手动进行词嵌入操作,使用
nn.Embedding 将输入的 input_ids(即词汇表中的ID)转换成向量表示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| class Bert(nn.Module):
def __init__(self, model_name, vocab_size, num_intent_labels, num_slot_labels, max_intents):
super().__init__()
self.embedding = nn.Embedding(vocab_size, 512)
self.encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8, batch_first=True)
self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=6)
self.intent_count_fc = nn.Linear(512, max_intents)
self.intent_classifier = nn.Linear(512, num_intent_labels)
self.slot_classifier = nn.Linear(512, num_slot_labels)
def forward(self, input_ids, attention_mask, token_type_ids=None):
embedded = self.embedding(input_ids)
key_padding_mask = (attention_mask == 0)
outputs = self.transformer_encoder(
src=embedded,
src_key_padding_mask=key_padding_mask
)
cls_output = outputs[:, 0, :]
intent_count_logits = self.intent_count_fc(cls_output)
intent_logits = self.intent_classifier(cls_output)
slot_logits = self.slot_classifier(outputs)
return intent_count_logits, intent_logits, slot_logits
|
TransformerEncoderLayer 是Transformer中的一个基本编码层,它由多头自注意力机制和前馈神经网络组成,主要用于对输入的序列进行处理。
- 输入:
src(输入张量):通常是 [batch_size, seq_len, embedding_size] 的张量。这里 embedding_size 就是你模型中每个token的表示大小,通常与输入的嵌入维度相同。src_key_padding_mask(填充掩码):这是一个形状为 [batch_size, seq_len] 的布尔张量,指示哪些位置是填充token,模型将忽略这些位置的计算。
- 输出:
- 输出张量:Transformer Encoder层会输出处理后的张量,形状为
[batch_size, seq_len, d_model],其中 d_model 是输入和输出的嵌入维度。这个输出代表了经过注意力机制和前馈网络处理后的每个token的表示。
TransformerEncoder 是多个 TransformerEncoderLayer 堆叠起来的组成部分,通常用来对序列进行更深层次的表示学习。通过多个Encoder层的堆叠,模型可以捕获输入序列中的更复杂的模式。
- 输入:
src:与 TransformerEncoderLayer 的输入相同,形状为 [batch_size, seq_len, d_model],即输入序列的嵌入表示。src_key_padding_mask:同样是一个布尔张量,用于指示哪些位置是填充token,形状为 [batch_size, seq_len]。
- 输出:
- 输出张量:
TransformerEncoder 的输出是每个输入token经过所有堆叠的Encoder层之后的最终表示,形状为 [batch_size, seq_len, d_model]。
cls_output = outputs[:, 0, :]解释:
- **
:**:代表选择所有批次中的样本(即选择所有的 batch_size)。
- **
0**:表示选择每个序列中的第一个token([CLS] token)。由于在BERT和Transformer模型中,第一个token是用来表示整个句子或文本的语义信息的,因此我们常常提取它用于分类任务。
- **
:**:代表选择所有隐藏层的维度,即选取每个token在 hidden_size 维度上的表示。
- 因此,
outputs[:, 0, :] 的作用是从每个样本的输出中提取第一个token的表示,输出的形状是 [batch_size, hidden_size]。
[!info] 新版本torch的区别:
注意我的torch环境是2.2.2的,但是2.6版本的torch对TransformerEncoder进行了重写,相关参数如下:
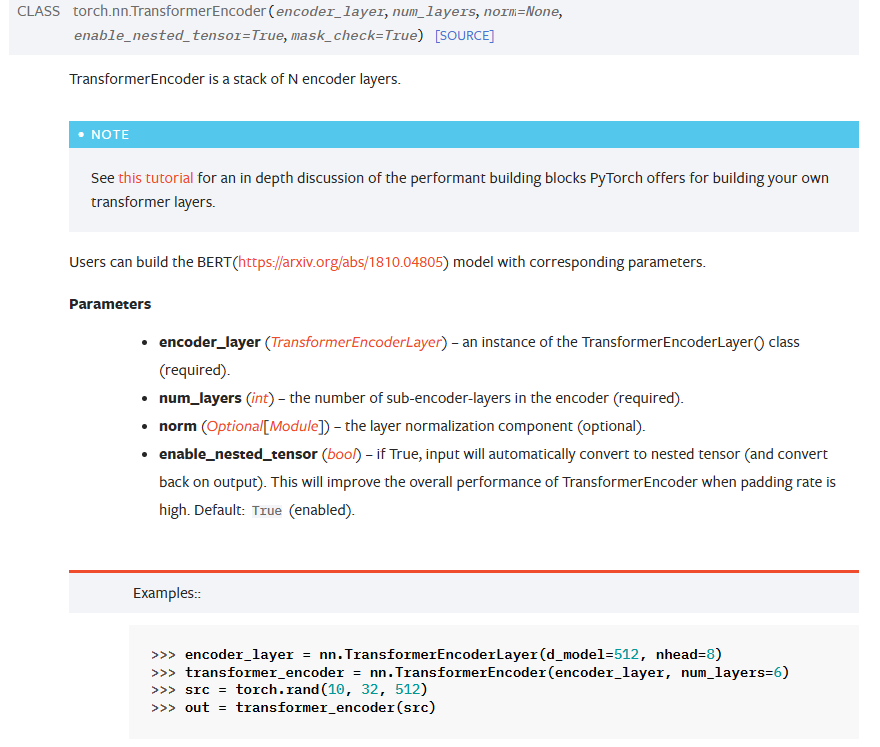
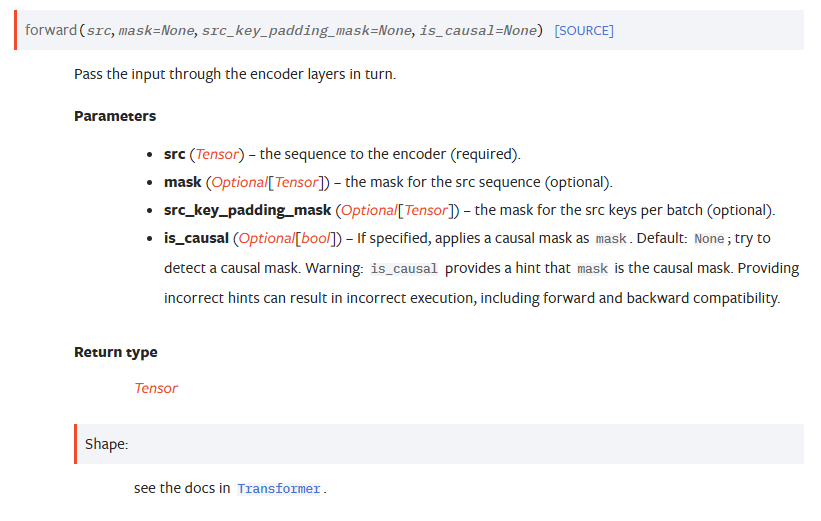
这样就不需要强制让attention_mask变成bool类型,可以传入tensor了
两者区别:
- **
TransformerEncoderLayer**:是一个单独的Transformer编码层,包含自注意力机制和前馈网络,输出每个token的表示。
- **
TransformerEncoder**:是由多个 TransformerEncoderLayer 组成的层堆栈,对输入序列进行编码,输出每个token的最终表示。
实验结果
有点长,没有完全跑完,但感觉插槽填充的结果不太对劲,得找个时间仔细一点debug
手动实现
手动实现Encoder部分,建议回去再复习一下Encoder架构:
- Embedding
- Position Encoding
- Multi-head Attention
- shortcut&LayerNorm
- Feed-forward network
- shortcut&LayerNorm
注意掩码区别
在PyTorch中,nn.Transformer 模块的掩码通常分为两类:
- **
src_key_padding_mask**:用于指示源序列中哪些位置是填充(padding)的位置。这个掩码会被传递到自注意力机制中,以防止模型在计算注意力时关注到填充部分。
- **
tgt_key_padding_mask**:用于指示目标序列中哪些位置是填充(padding)的位置。通常在序列到序列(seq2seq)任务中使用。
- **
src_mask**:用于指示源序列的特定位置是否应该被注意力机制忽略。在自回归模型(如GPT)中,src_mask 用于防止当前位置之后的token被注意。
PyTorch中的掩码参数和功能:
src_key_padding_mask: 通常是一个形状为 [batch_size, seq_len] 的布尔张量,其中填充的token的位置标记为 True 或 1,非填充的token位置标记为 False 或 0。tgt_key_padding_mask: 形状也是 [batch_size, seq_len],用于指示目标序列中的填充位置。src_mask: 形状为 [seq_len, seq_len],通常用于自回归模型中来阻止未来的信息泄漏,类似于遮挡注意力。
在Hugging Face的transformers库中,掩码的使用方法与PyTorch有所不同,尤其是在处理预训练模型(如BERT、GPT等)时。Hugging Face库中的掩码通常用于输入的 attention_mask 和 token_type_ids。
- **
attention_mask**:它是一个形状为 [batch_size, seq_len] 的张量,用于指示哪些位置是填充token。1 表示该位置为有效token,0 表示该位置是填充token,模型会忽略填充位置。
- 作用:与PyTorch中的
src_key_padding_mask 类似,用来指示模型哪些token是有效的,哪些是填充token。
- **
token_type_ids**:用于指示输入中不同句子的边界,特别是在任务如问答或句对任务(例如sentence_pair_classification)中,用来区分两个句子。0表示句子A,1表示句子B。
Hugging Face中的掩码参数和功能:
attention_mask: 形状为 [batch_size, seq_len],填充的token位置是0,有效的token位置是1,通常用于标记哪些token需要被关注,哪些是填充,避免模型将填充部分作为有效信息处理。token_type_ids: 形状为 [batch_size, seq_len],用于区分输入中的两个句子。
Embedding
这块差别不大
1
2
3
4
5
6
7
8
| class Embedding(nn.Module):
def __init__(self, vocab_size, d_model):
super(Embedding, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.d_model = d_model
def forward(self, x):
return self.embedding(x) * math.sqrt(self.d_model)
|
Position Encoding
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
class PositionalEncoding(nn.Module):
'''
Positional Encoding 层,用于给输入序列添加位置信息。
计算方式:
PE(pos,2i) = sin(pos/10000^(2i/d_model))
PE(pos,2i+1) = cos(pos/10000^(2i/d_model))
'''
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
seq_len = x.size(1)
pe = self.pe[:, :seq_len]
x = x + pe
return x
|
多头注意力
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
| class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads, dropout=0.1):
'''
:param d_model: 输入序列的维度
:param num_heads: 多头注意力的数量
:param dropout: dropout概率
'''
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0, "d_model必须被num_heads整除"
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.fc = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
'''
:param x: 输入序列,形状为(batch_size, seq_len, d_model)
:param mask: 掩码,形状为(batch_size, seq_len, seq_len)
:return: 输出序列,形状为(batch_size, seq_len, d_model)
'''
batch_size = x.size(0)
seq_len = x.size(1)
Q = self.W_q(x)
K = self.W_k(x)
V = self.W_v(x)
Q = Q.view(batch_size, seq_len, self.num_heads, self.d_k).permute(0, 2, 1, 3)
K = K.view(batch_size, seq_len, self.num_heads, self.d_k).permute(0, 2, 1, 3)
V = V.view(batch_size, seq_len, self.num_heads, self.d_k).permute(0, 2, 1, 3)
scores = torch.matmul(Q, K.transpose(-2, -1) / math.sqrt(self.d_k))
if mask is not None:
mask = mask.unsqueeze(1).unsqueeze(1)
scores = scores.masked_fill(mask == 0, float('-inf'))
attn = self.softmax(scores)
attn = self.dropout(attn)
context = torch.matmul(attn, V)
context = context.permute(0, 2, 1, 3).contiguous()
context = context.view(batch_size, seq_len, self.d_model)
out = self.fc(context)
return out
|
FFN
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
'''
:param d_model: 输入/输出序列的维度
:param d_ff: 前馈网络的隐藏层维度
:param dropout: dropout概率
'''
super(PositionwiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
self.relu = nn.ReLU()
def forward(self, x):
'''
:param x: 输入序列,形状为(batch_size, seq_len, d_model)
:return: 输出序列,形状为(batch_size, seq_len, d_model)
'''
out = self.fc1(x)
out = self.relu(out)
out = self.dropout(out)
out = self.fc2(out)
out = self.dropout(out)
return out
|
Encoder封装
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
'''
:param d_model: 输入/输出序列的维度
:param num_heads: 多头注意力的数量
:param d_ff: 前馈网络的隐藏层维度
'''
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.layer_norm1 = nn.LayerNorm(d_model, eps=1e-6)
self.layer_norm2 = nn.LayerNorm(d_model, eps=1e-6)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
'''
:param x: 输入序列,形状为(batch_size, seq_len, d_model)
:param mask: 掩码,形状为(batch_size, seq_len, seq_len)
:return: 输出序列,形状为(batch_size, seq_len, d_model)
'''
attn_out = self.self_attn(x, mask)
x = x + self.dropout(attn_out)
x = self.layer_norm1(x)
ff_out = self.feed_forward(x)
x = x + self.dropout(ff_out)
x = self.layer_norm2(x)
return x
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
class TransformerEncoder(nn.Module):
def __init__(self, d_model=512, n_heads=8, d_ff=2048, num_layers = 6, dropout=0.1, max_len = 5000, use_pos_encoding=True):
'''
:param d_model: 输入/输出序列的维度
:param n_heads: 多头注意力的数量
:param d_ff: 前馈网络的隐藏层维度
:param num_layers: 编码器的层数
:param dropout: dropout概率
:param max_len: 输入序列的最大长度
:param use_pos_encoding: 是否使用位置编码
'''
super(TransformerEncoder, self).__init__()
self.use_pos_encoding = use_pos_encoding
if use_pos_encoding:
self.pos_encoding = PositionalEncoding(d_model, max_len=max_len)
self.layers = nn.ModuleList([
EncoderLayer(d_model, n_heads, d_ff, dropout)
for _ in range(num_layers)
])
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(self, x, mask=None):
'''
:param x: 输入序列,形状为(batch_size, seq_len, d_model)
:param mask: 掩码,形状为(batch_size, seq_len, seq_len)
:return: 输出序列,形状为(batch_size, seq_len, d_model)
'''
if self.use_pos_encoding:
x = self.pos_encoding(x)
for layer in self.layers:
x = layer(x, mask)
x = self.layer_norm(x)
return x
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
| class MyTransformer(nn.Module):
def __init__(self, vocab_size, num_intent_labels, num_slot_labels, max_intents,
d_model=512, n_heads=8, d_ff=2048, num_layers=6, dropout=0.1, max_len=5000):
"""
参数:
vocab_size: 词汇表大小
num_intent_labels: 意图类别数
num_slot_labels: 槽位类别数
max_intents: 最大意图数量
d_model: 模型维度
n_heads: 多头注意力头数
d_ff: 前馈网络隐藏层维度
num_layers: Transformer层数
dropout: dropout概率
max_len: 最大序列长度
"""
super().__init__()
self.embedding = Embedding(vocab_size, d_model)
self.position_encoding = PositionalEncoding(d_model, max_len)
self.encoder = TransformerEncoder(
d_model=d_model,
n_heads=n_heads,
d_ff=d_ff,
num_layers=num_layers,
dropout=dropout,
max_len=max_len
)
self.intent_count_head = nn.Linear(d_model, max_intents)
self.intent_head = nn.Linear(d_model, num_intent_labels)
self.slot_head = nn.Linear(d_model, num_slot_labels)
self._init_weights()
def _init_weights(self):
"""初始化模型参数"""
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, input_ids, attention_mask, token_type_ids):
"""
前向传播
参数:
input_ids: 输入token ids [batch_size, seq_len]
attention_mask: 注意力掩码 [batch_size, seq_len]
返回:
intent_count_logits: 意图数量预测 [batch_size, max_intents]
intent_logits: 意图分类 [batch_size, num_intent_labels]
slot_logits: 槽位预测 [batch_size, seq_len, num_slot_labels]
"""
x = self.embedding(input_ids)
x = self.position_encoding(x)
encoder_output = self.encoder(x, mask=~attention_mask)
cls_output = encoder_output[:, 0, :]
intent_count_logits = self.intent_count_head(cls_output)
intent_logits = self.intent_head(cls_output)
slot_logits = self.slot_head(encoder_output)
return intent_count_logits, intent_logits, slot_logits
|
实验结果
跑3个Epoch实验的时候就发现效果其实跟Bert正常的效果差不多了:
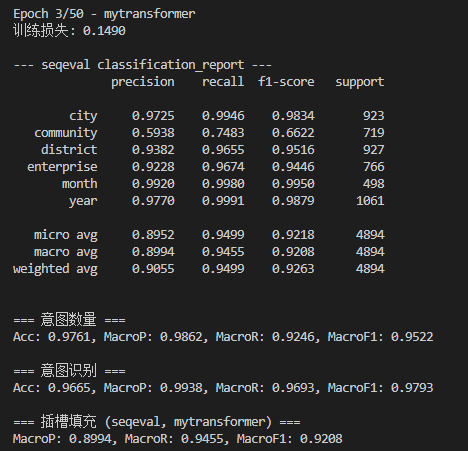
说明应该没写错()