迁移学习与微调
应用前提
数据与预想的任务不直接相关
做法
借助预训练模型泛化到我们自己的数据集上
当数据集较小时:
冻结前面的层,只训练最后一层全连接的分类层,实现微调(fine-tuning)
数据集较大时:
多往前训练几层

卷积层不会动
用冻结的权重进行特征抽取
存在4种情况
CS231n里面的举例:
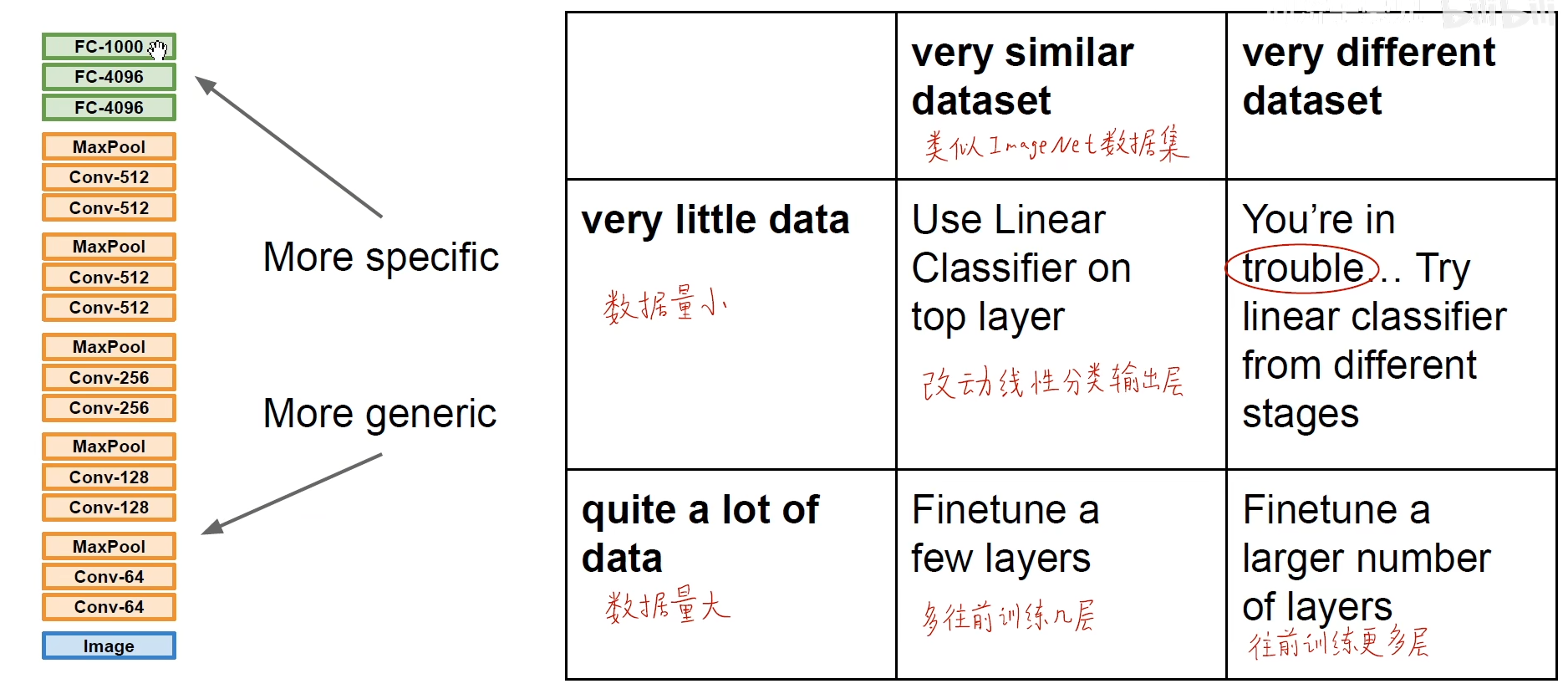
数据集小,数据相似
替换最后的全连接层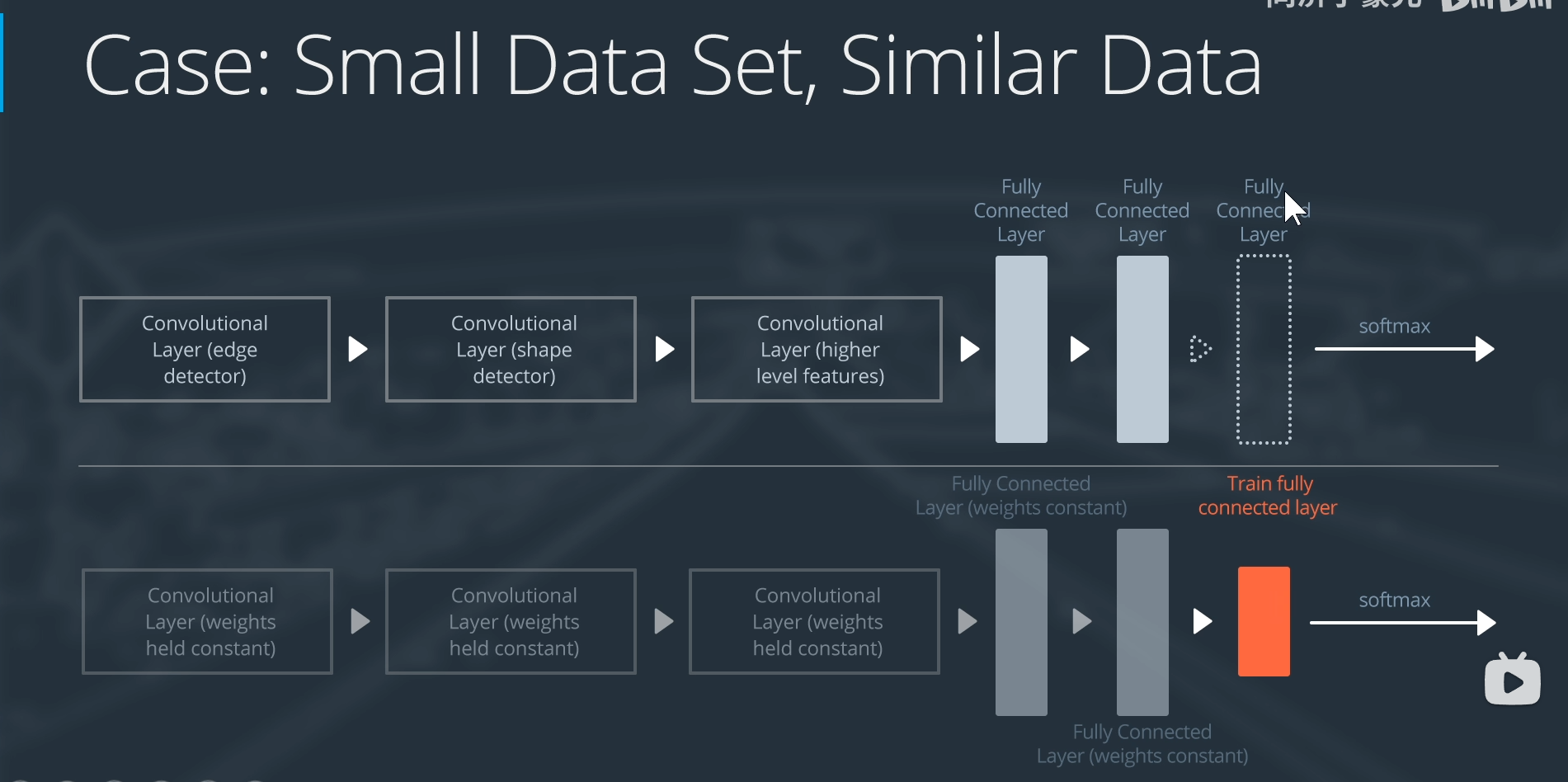
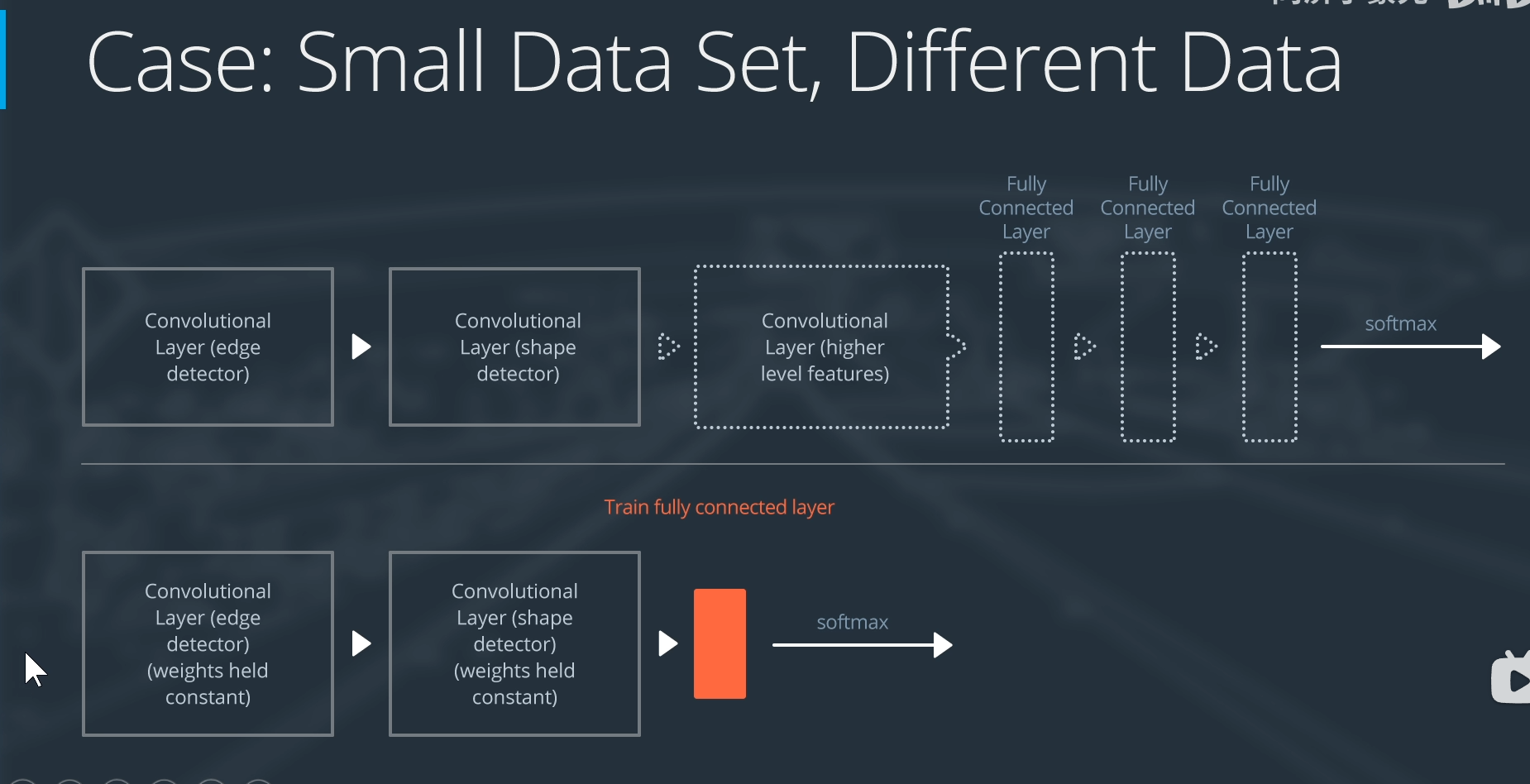
数据集小,数据不太一样
放弃全连接层和最后部分提取高阶特征的卷积层,重新设计全连接层
数据集大,数据相似
不进行冻结,权重基于预训练模型,再进一步训练
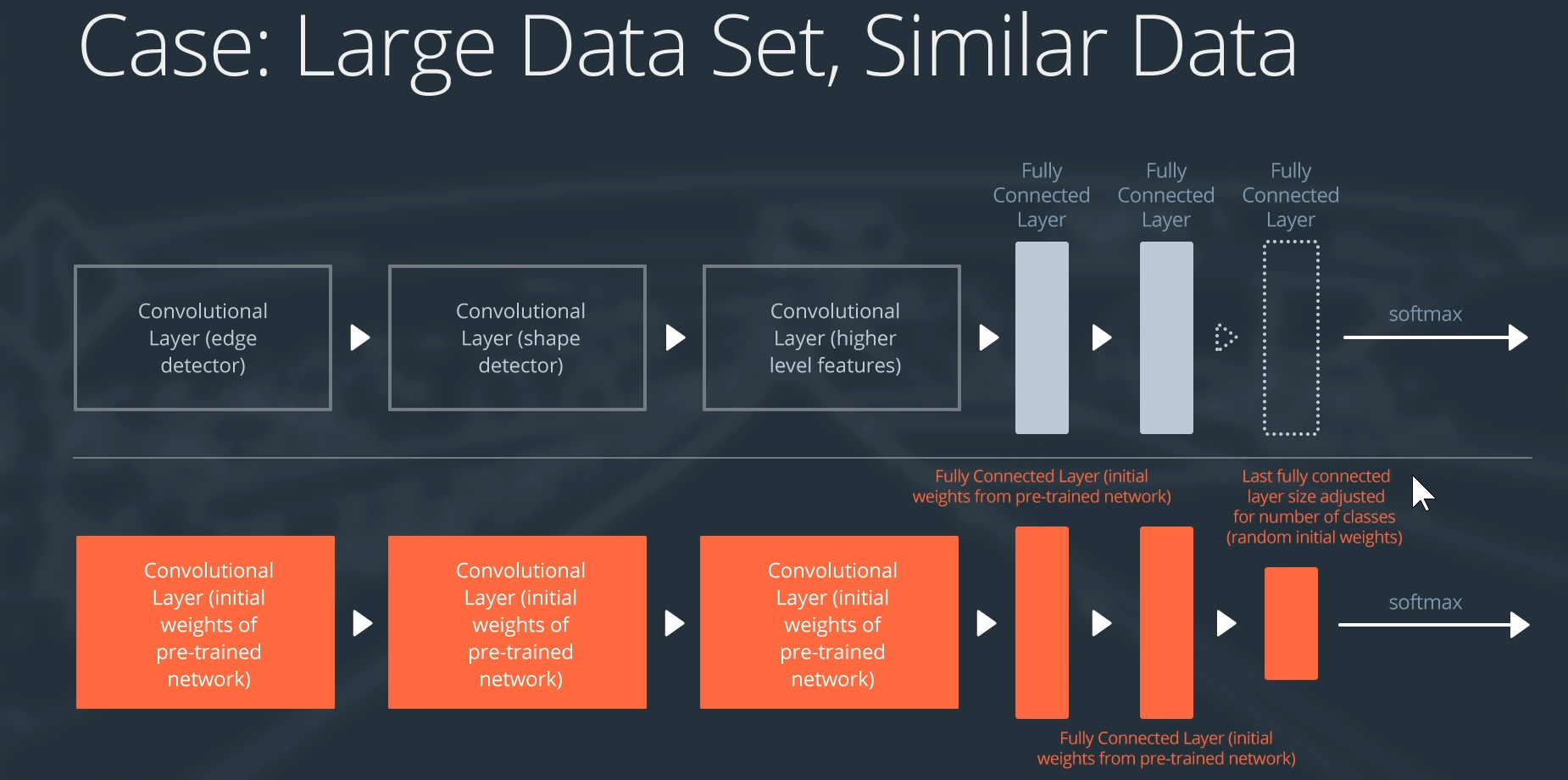
数据量大,数据集不大相同
可以所有层在预训练模型权重上训练(同上)
经典的预训练模型
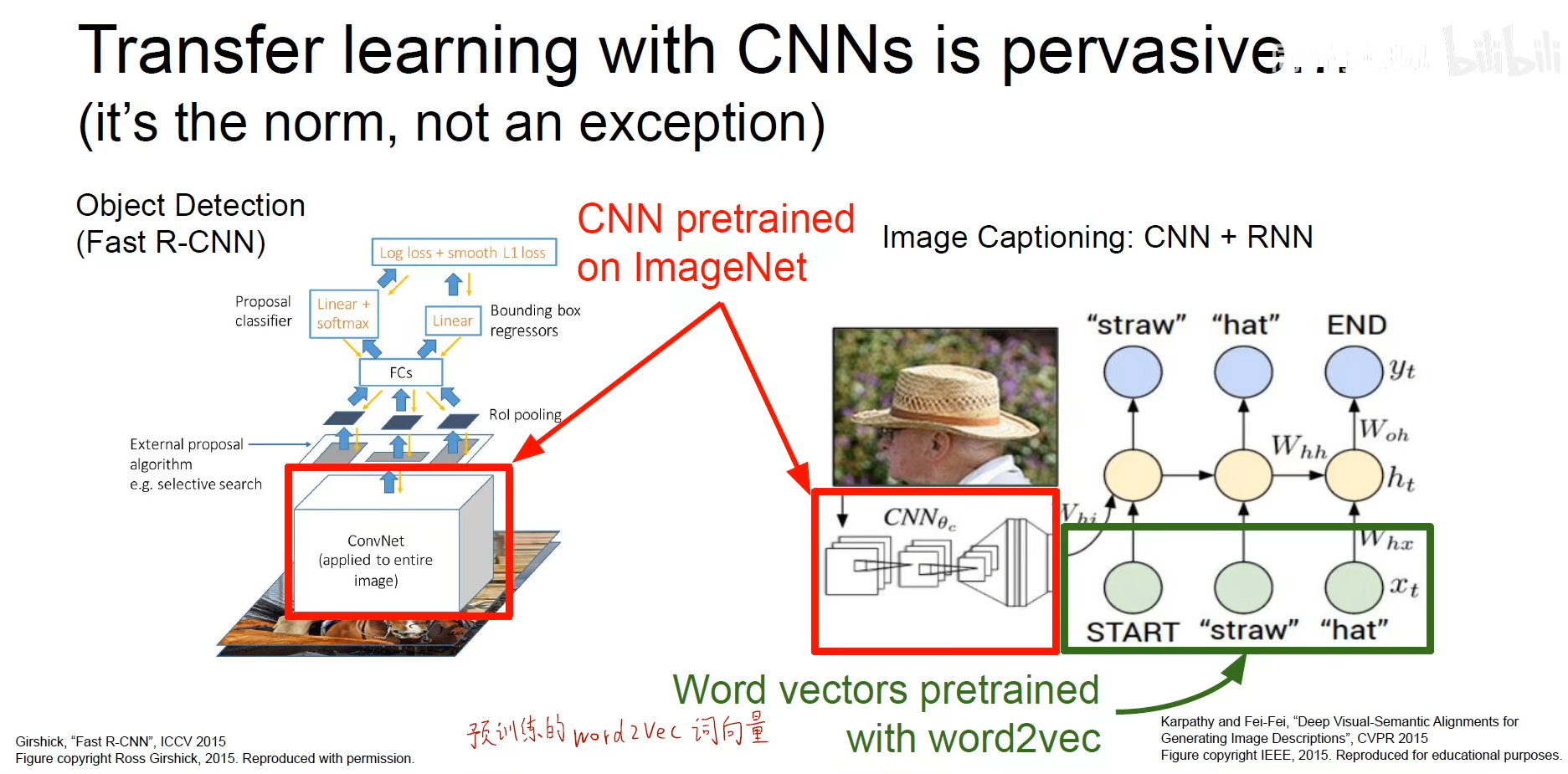
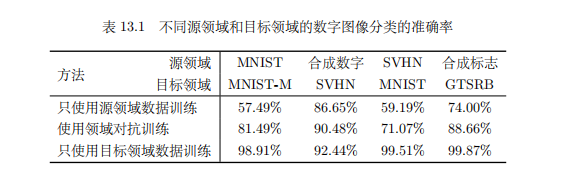
但是预训练模型不是万能的,He 2018 使用预训练模型与随机初始化模型进行对比,发现几轮后效果差不多,只是预训练模型可以加速收敛
[!ques] 数据集不够大的处理思路
- 找一个类似的大数据集训练模型
- 对模型进行迁移学习和微调泛化到小数据集上
深度学习框架提供了大量预训练模型库

迁移学习的细节
卷积神经网络提取特征的思路:
- 逐步细化,一开始提取边缘,后面提取部件,逐渐复杂
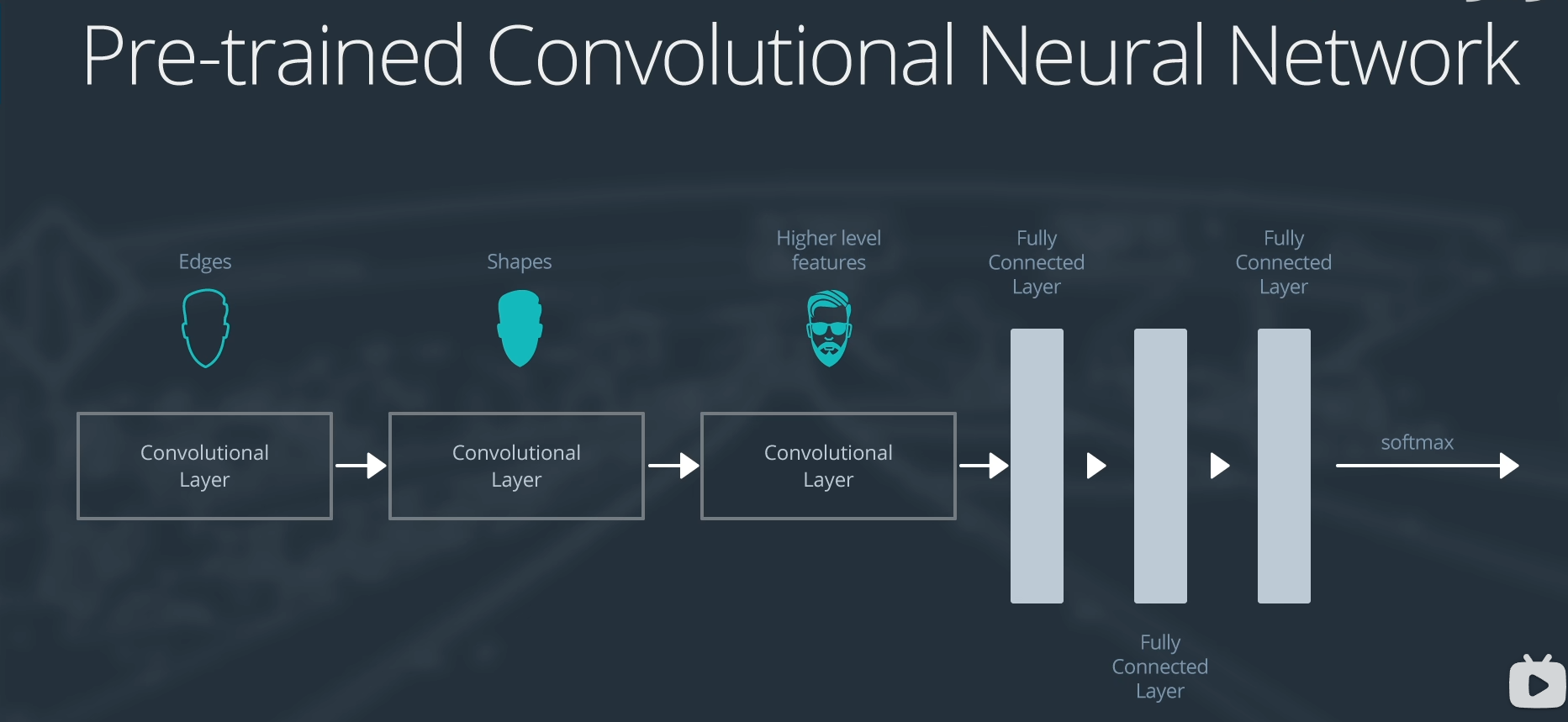
我们认为提取的特征是通用的,可以进行互相替换的。于是提出可以把前面的层进行冻结,只训练后面的全连接层
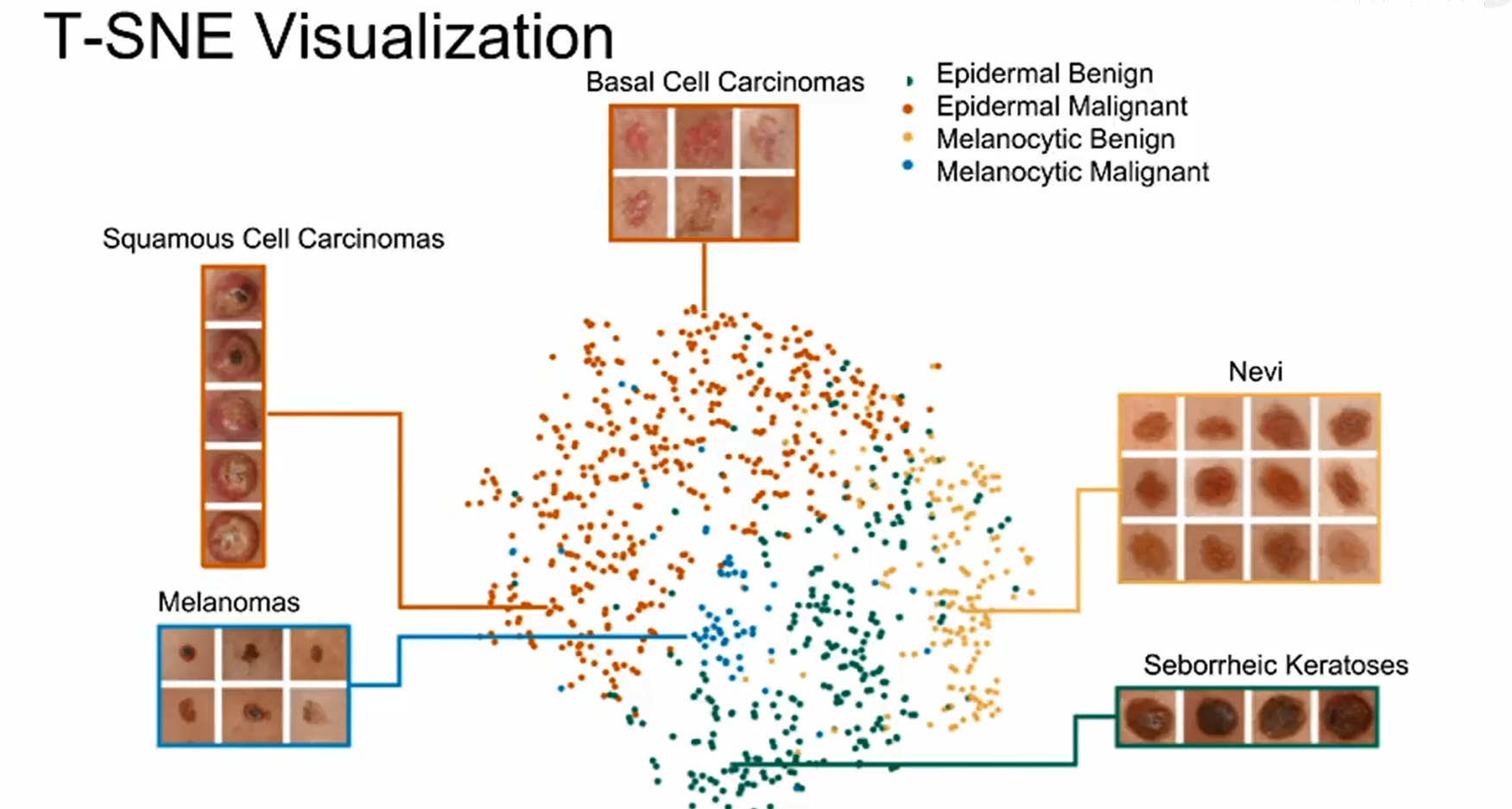
例子:皮肤癌数据集
基于Inception-v3
混淆矩阵
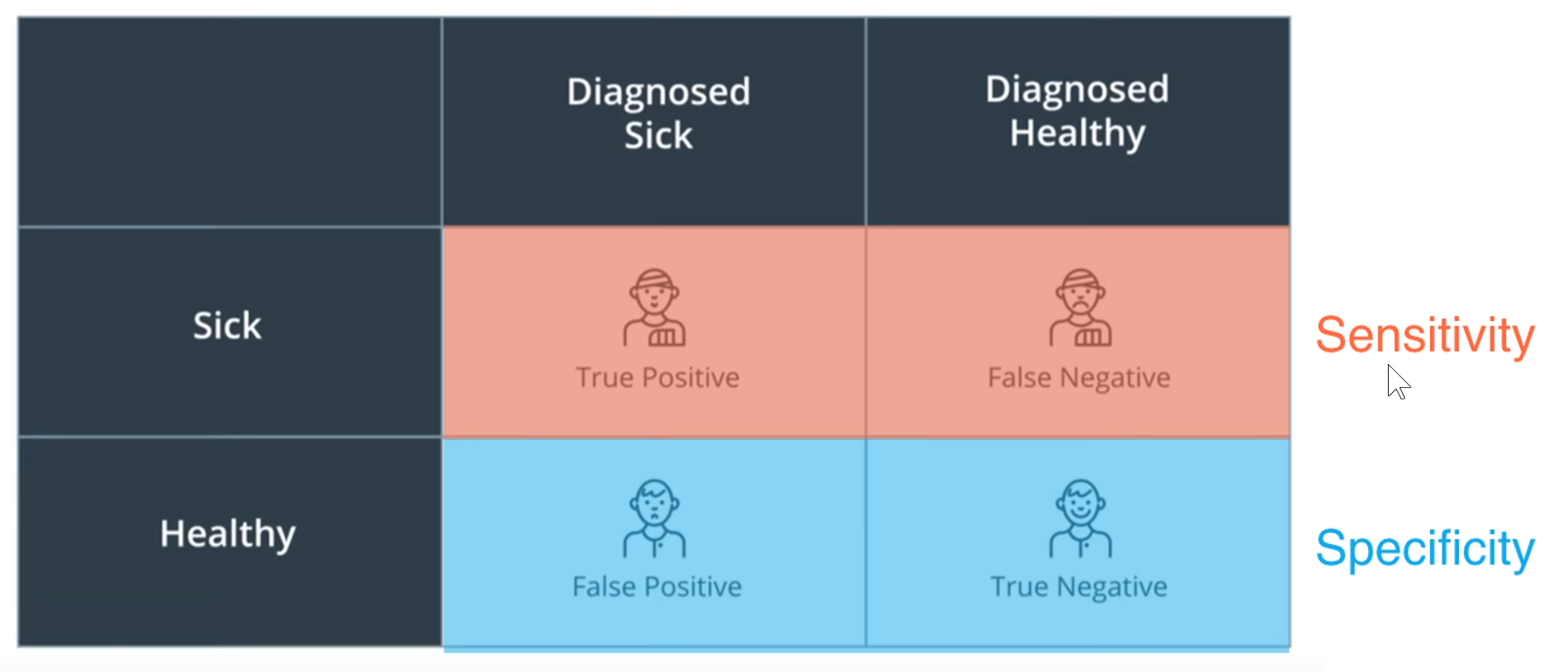
sensitivity(ReCall): 得了病的有多少被检测出病
specificity: 健康的人有多少被检测出健康
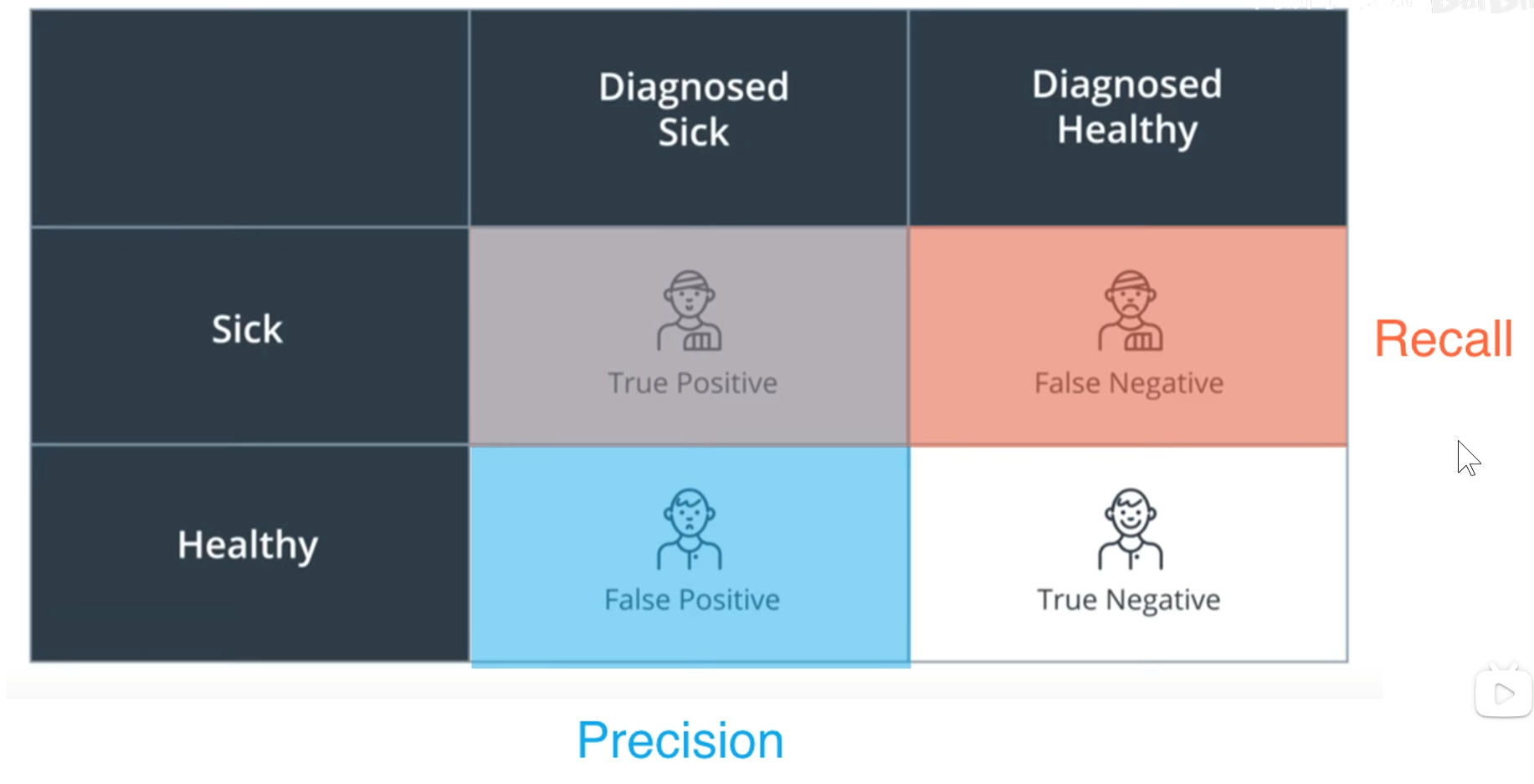
prisition:诊断为得病的人有多少真的得病
可视化
哪些容易被误分类
saliency map表示病灶区域(梯度敏感区)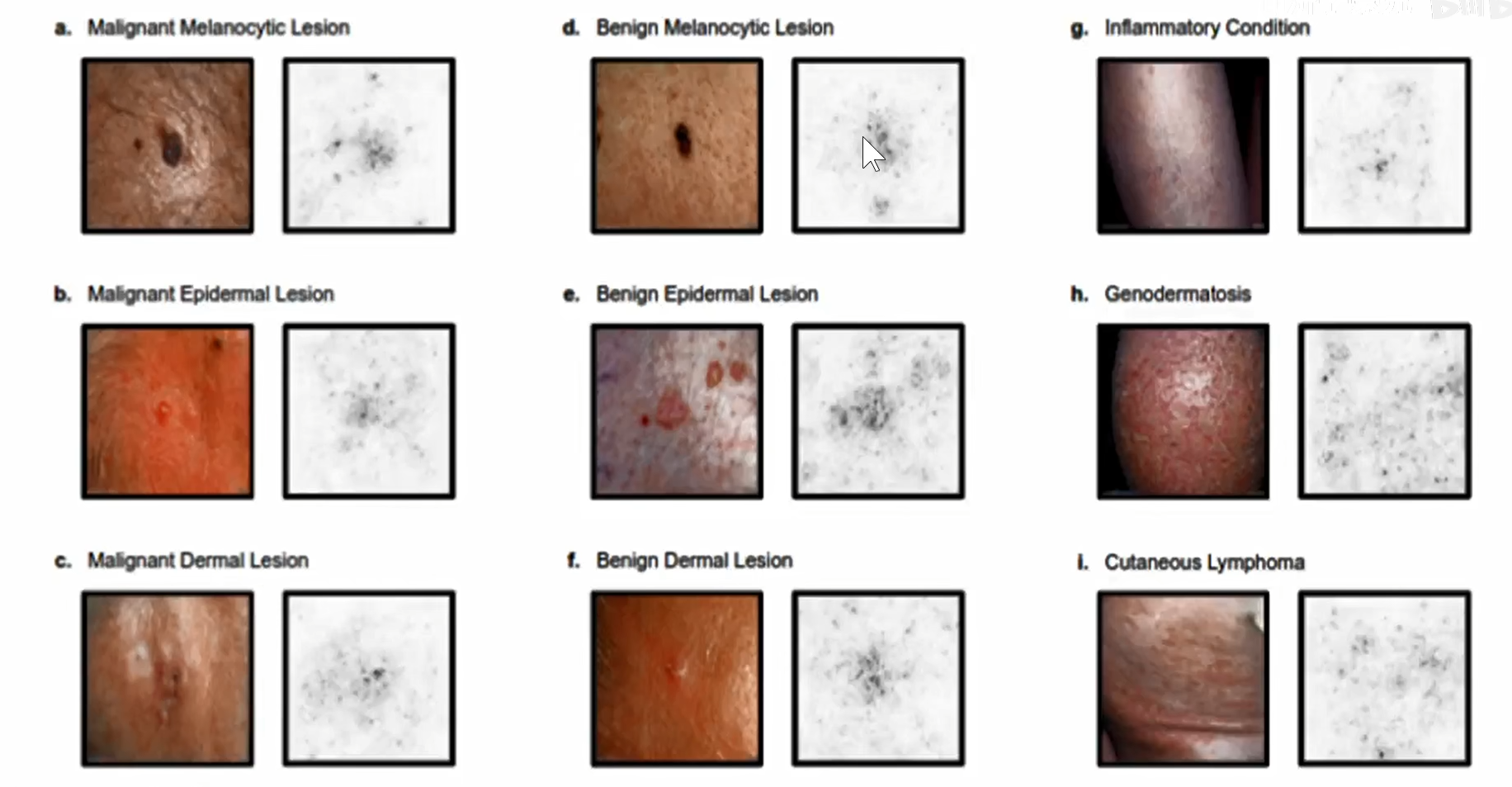
多分类混淆矩阵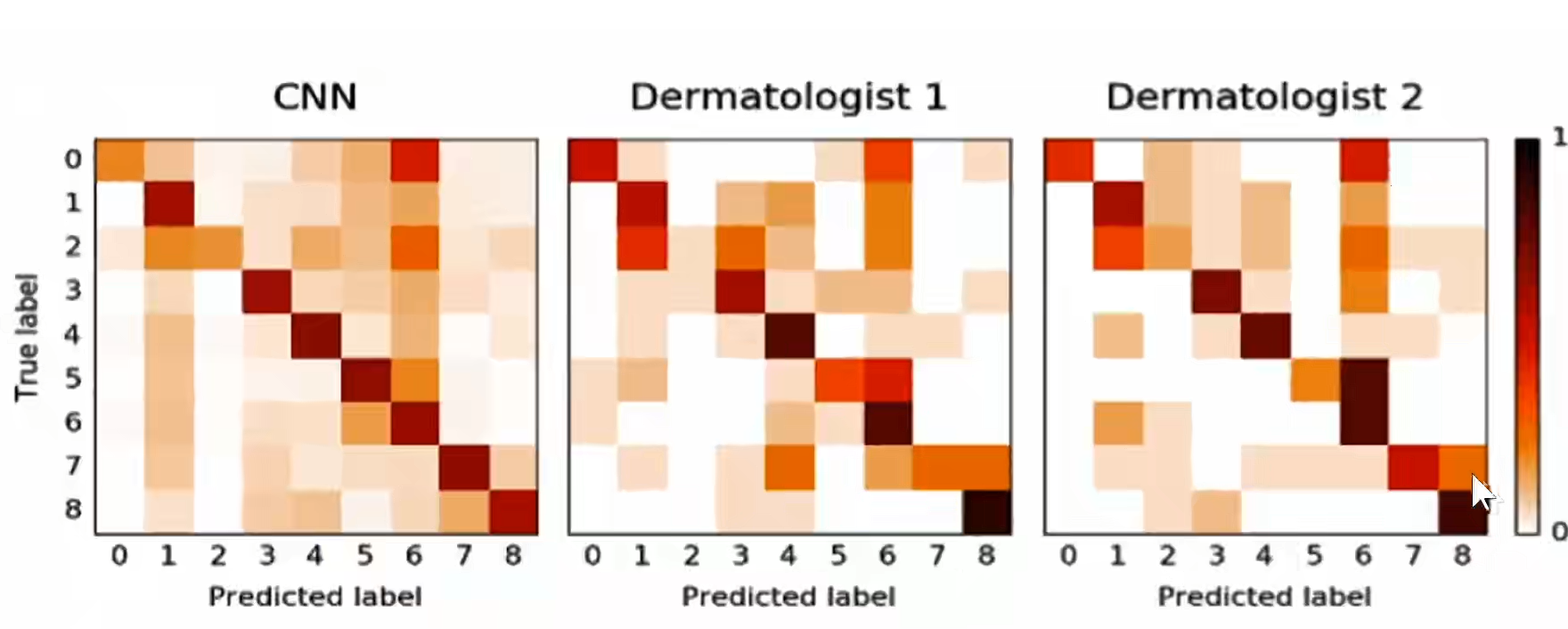
如何设计迁移学习
用一半数据训练A模型,再用另外一半数据训练B模型
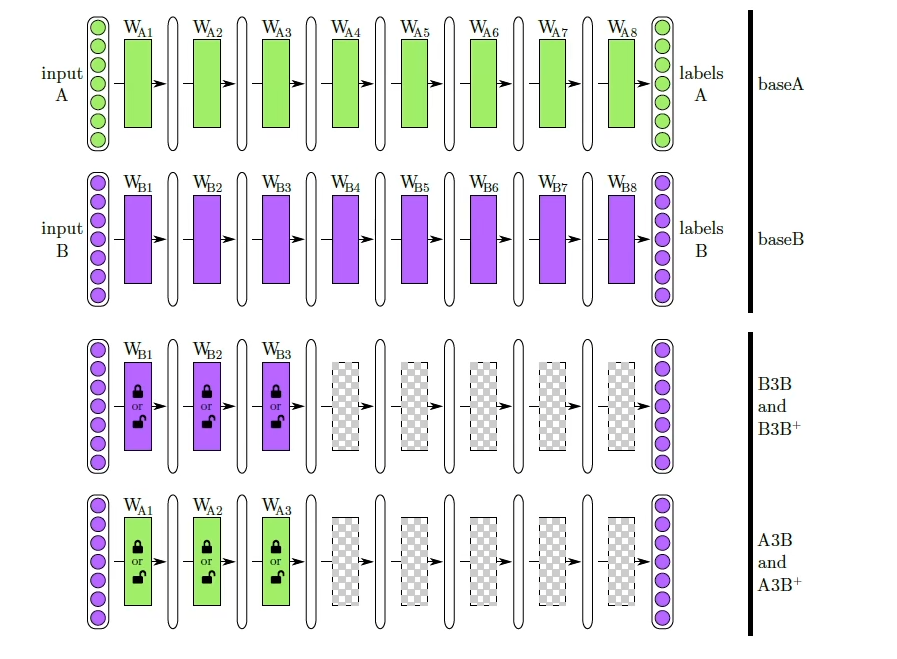
冻结B模型前3层:B3B,不冻结:B3B+
冻结A模型前3层,在B模型上测试:A3B,不冻结:A3B+
结果: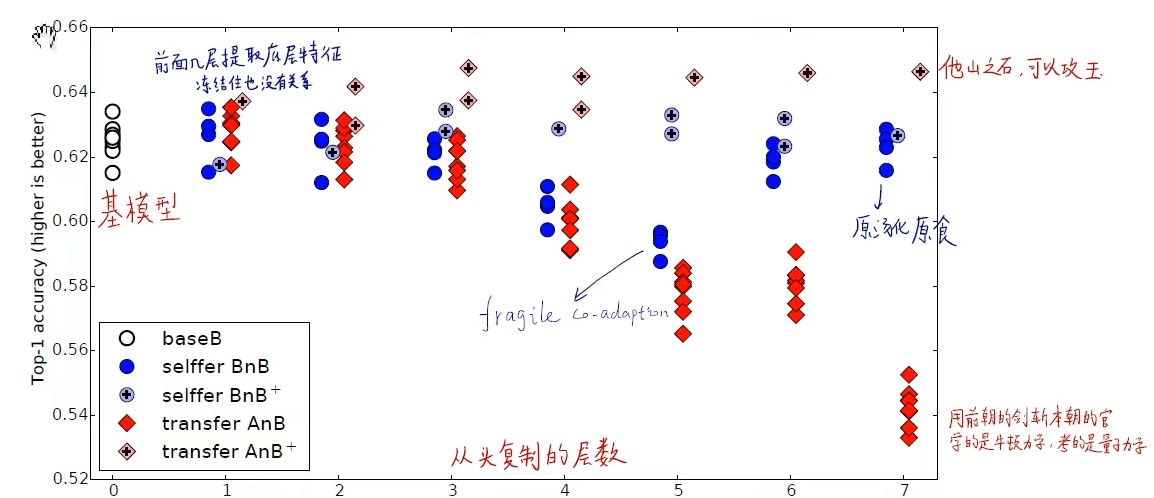
卷积层层与层之间会存在联合适应性,如果冻结了某个层但其他层不冻结可能会破坏耦合
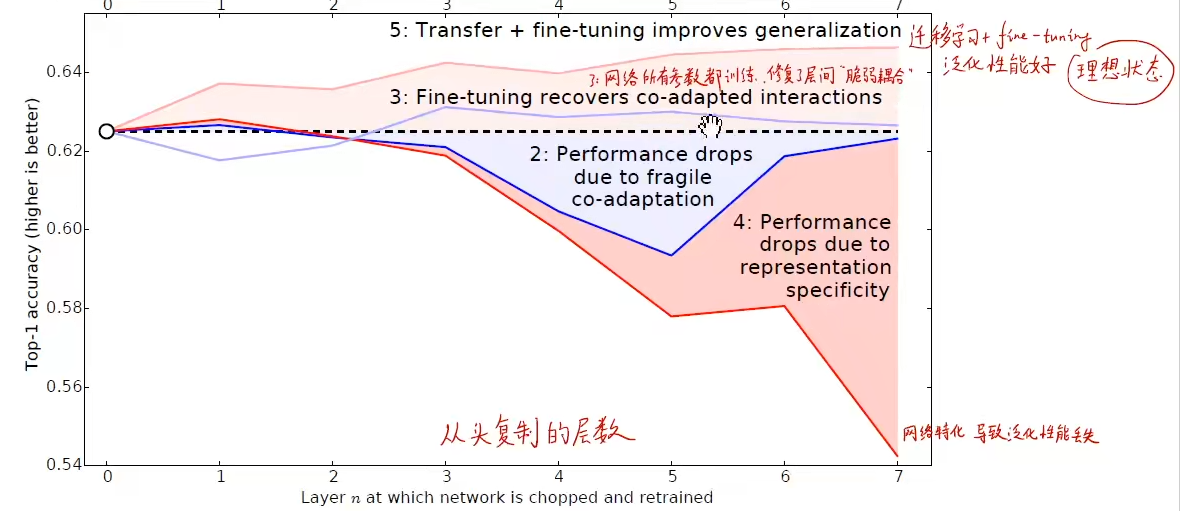
另一种讲法
李宏毅ML2021中介绍: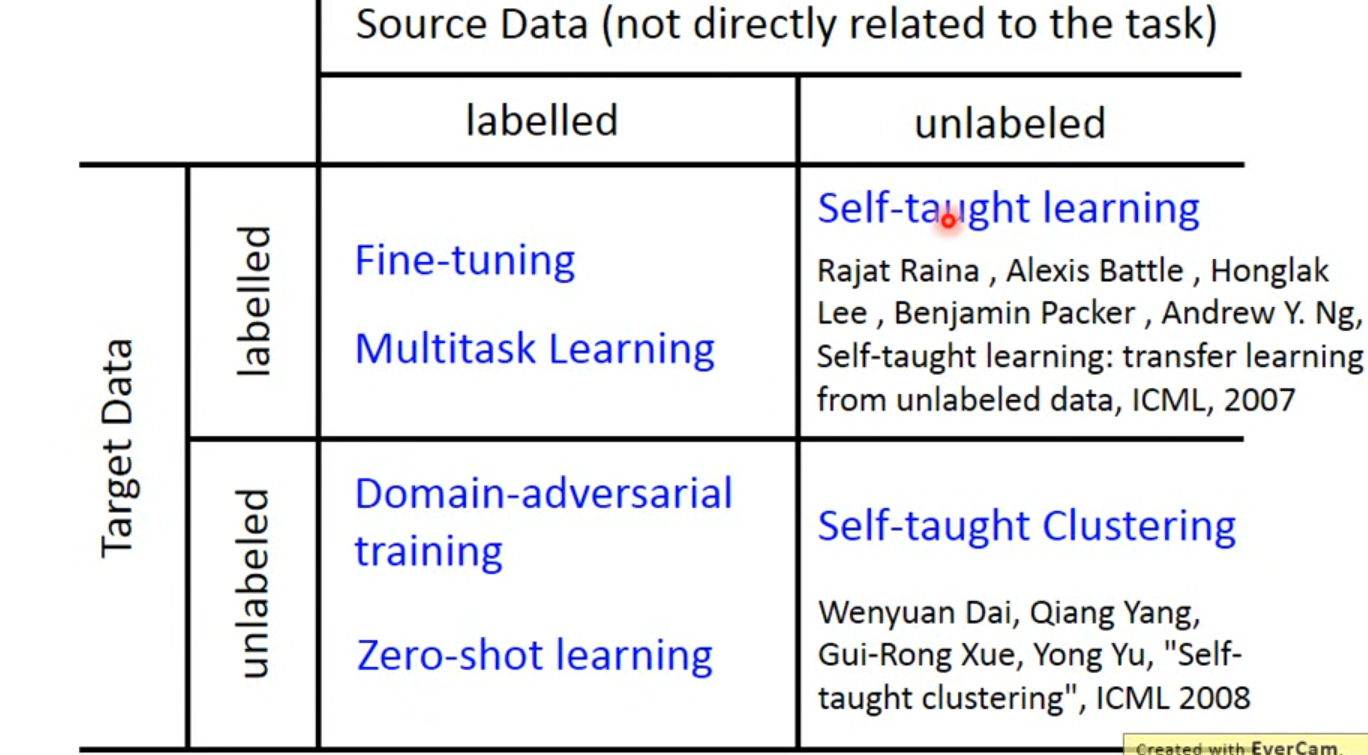
Model Fine-tuning
- 任务描述
- Target data:$(x^t, y^t)$ 非常少 (#Oneshot)
- Source data: $(x^s,y^s)$ 非常大
- 举例,speaker adaptation:
- Target: 某个人物的audio data
- Source: 非常多人的audio data
Idea: 先在source data上训练,然后再到Target data做fine-tune
eg. 拿欧洲语言做中文语言的transfer
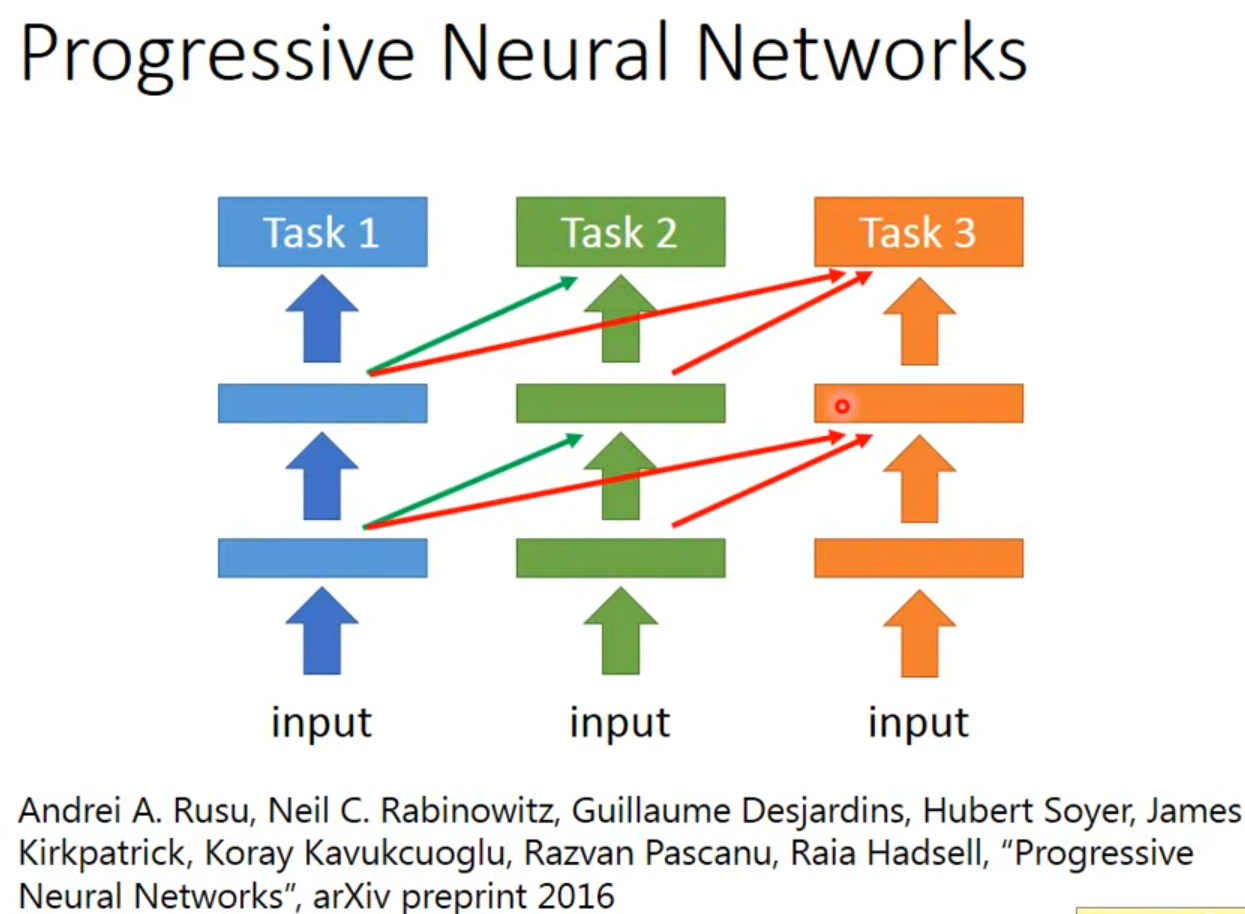
[!question] 怎么判断两个数据集像不像
一种想法是,先训练 Task1,然后 Task2,它的每个hidden layer都会去接前面Net1某一个hidden layer的output。这样即使非常不像,Task1不会被影响,Task2借用Task1的参数,但可以把这些参数直接设成0,这样也不会影响自己的Performance
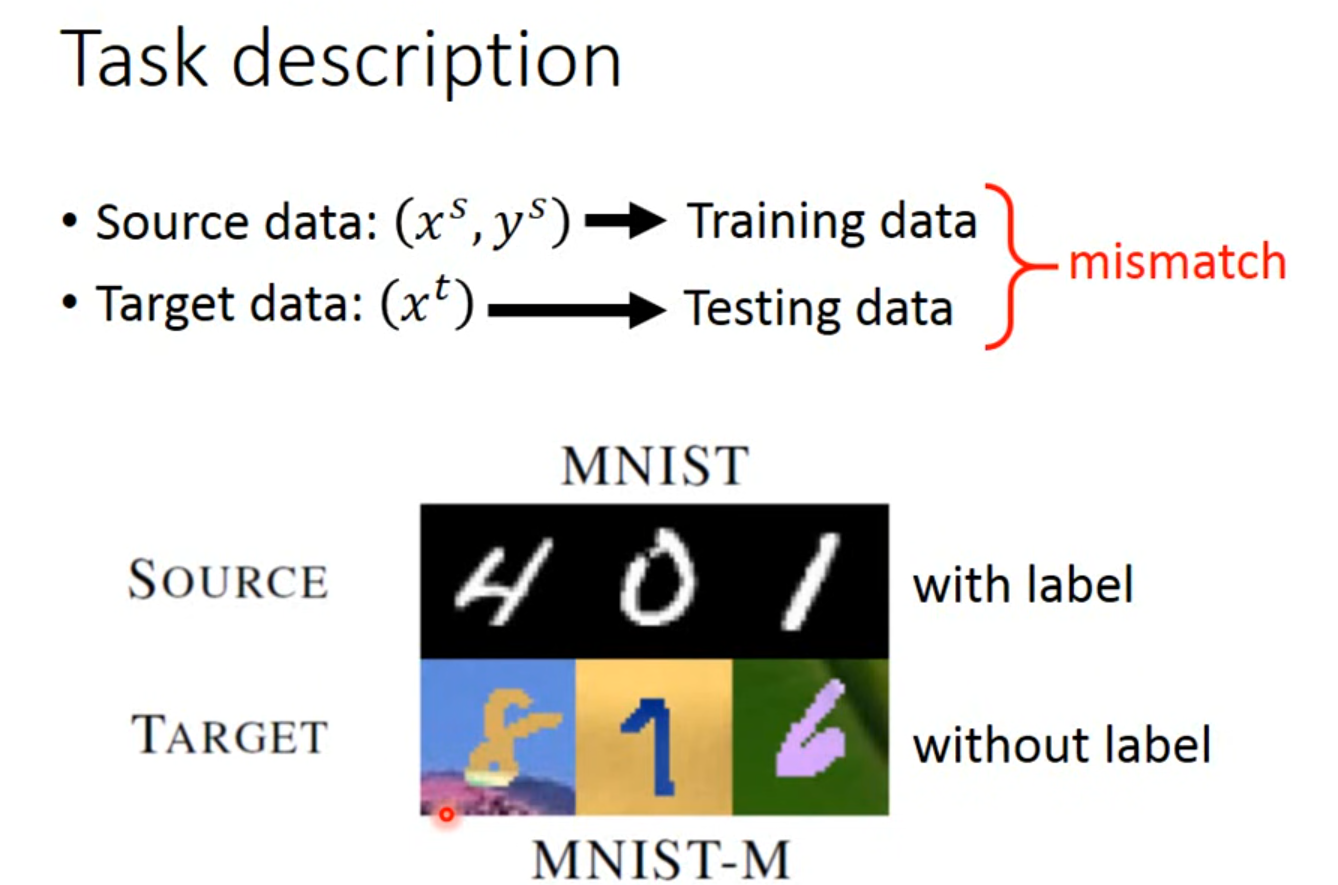
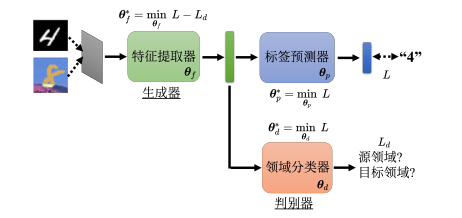
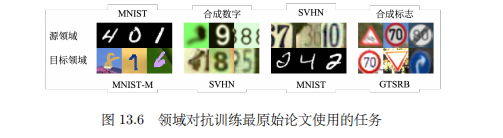
Domain-adversarial training
Target data没有标注,Source data有标注
这两个不是match的
但可以把source data当成training data,把target data当成testing data来处理
重新回到CNN
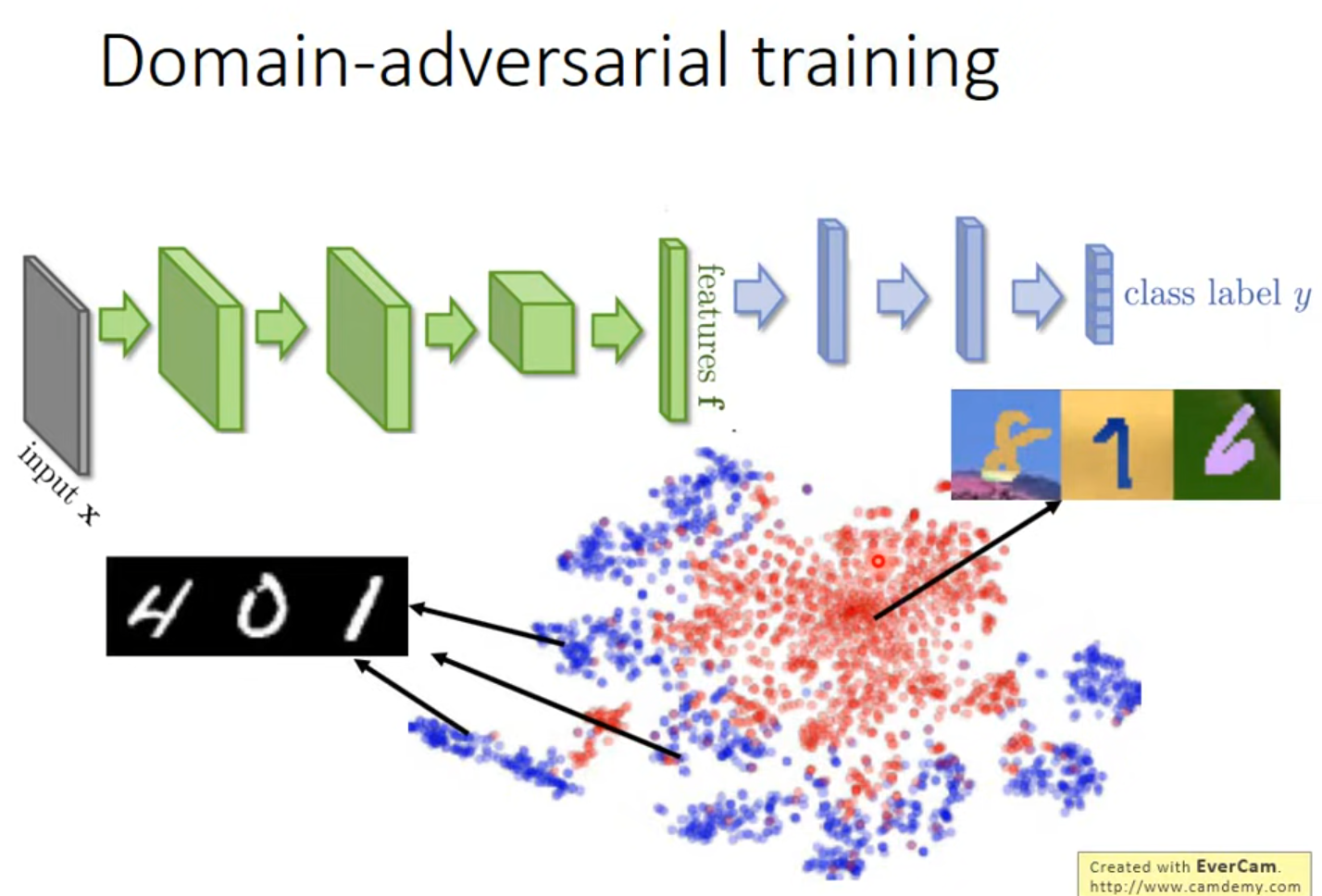
绿色的部分是作为特征抽取的,以MNIST为例,抽取特征后进行t-SNE降维,可以很明显看到数据被投影成了9个类,但是把MNIST-M输入后,数据并没有很好的表征。
这是因为domain不同产生的影响。于是,能不能去除这种影响?即,能不能让红色和蓝色进行均匀混合?
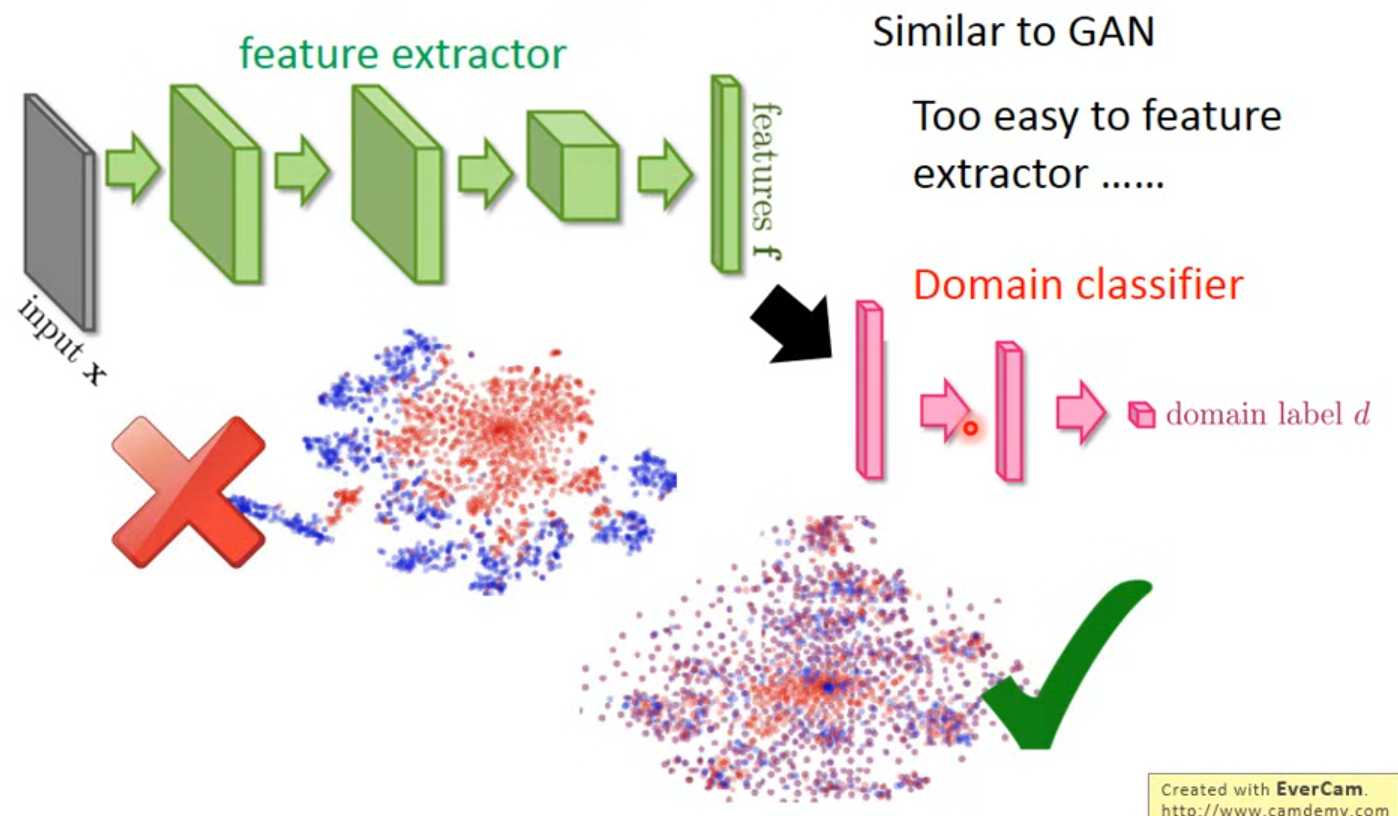
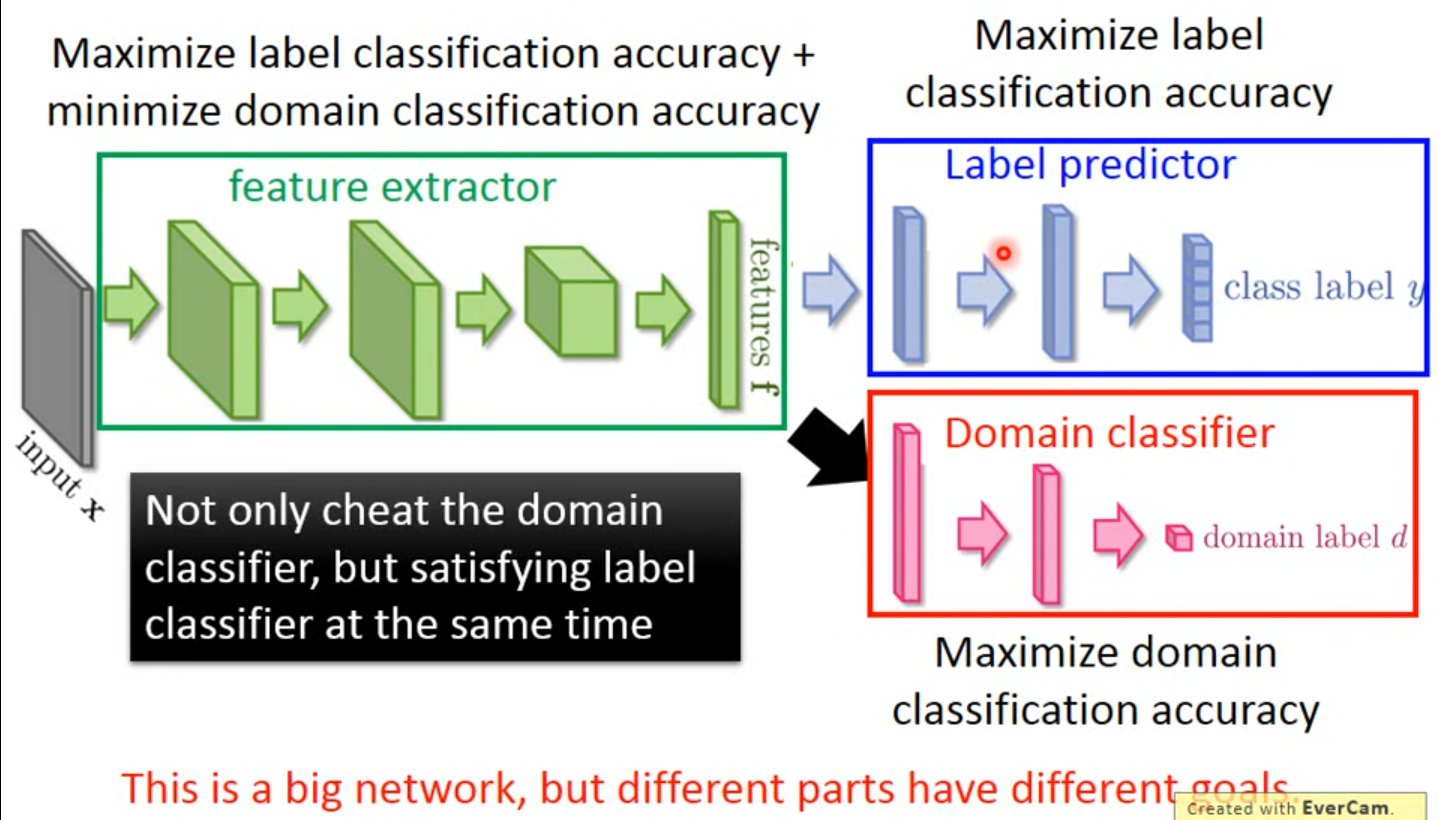
于是任务转化为训练一个domain classifier 和label predictor,既能够骗过domain classifier,同时还可以让predicter正常预测
三个网络的目标有所区别:
- feature extractor:最大化分类准确度,最小化领域分类准确率(需要骗过domain classifier)
- Label predictor: 最大化分类准确率
- Domain classifier:最大化领域分类准确率
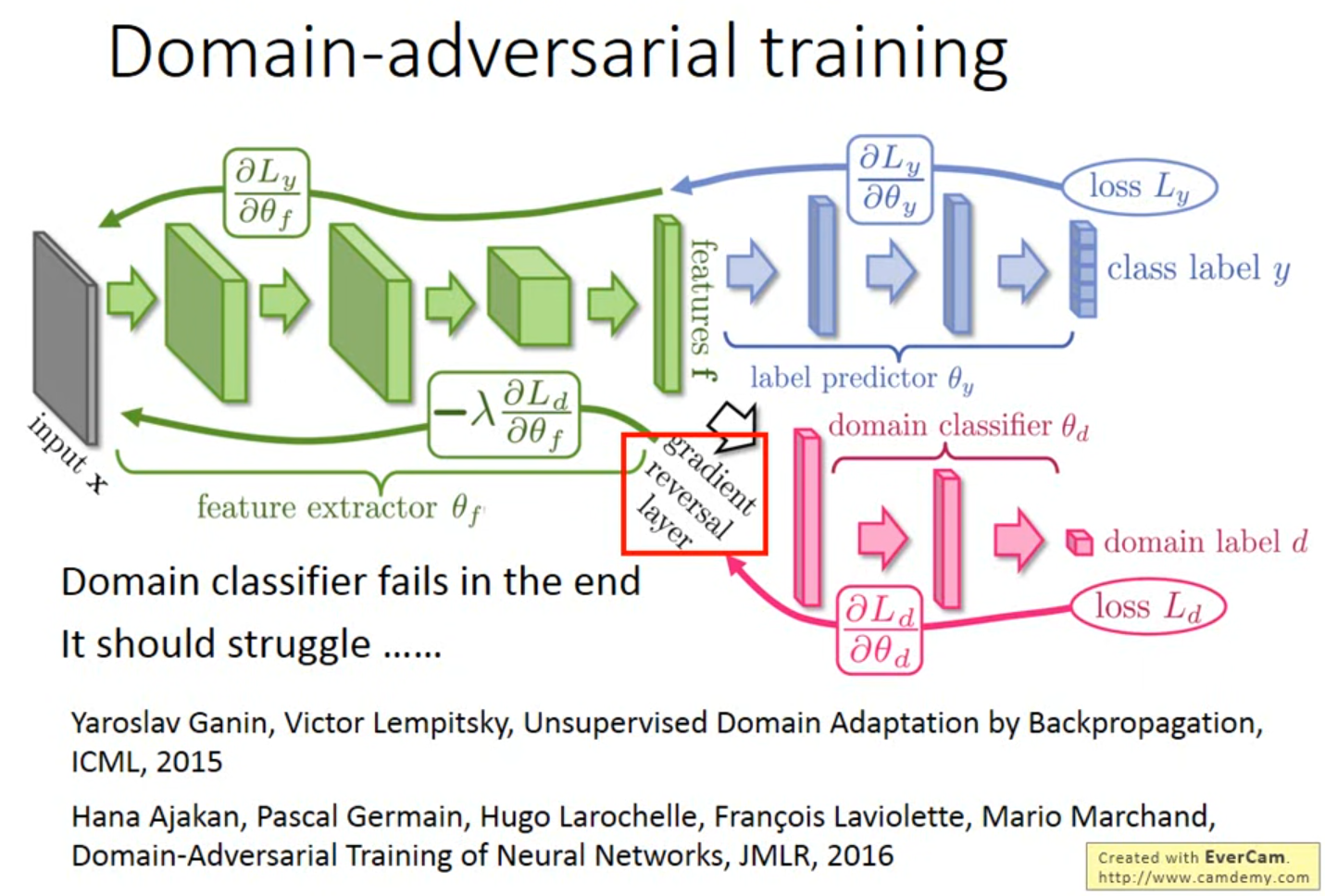
[!question] 怎么骗过domain?
feature extractor每次都对domain传来的梯度乘-1,即始终往domain需要的相反方向走,让domain迷惑
不太好训练
需要让domain classifer不断训练,避免让它传0
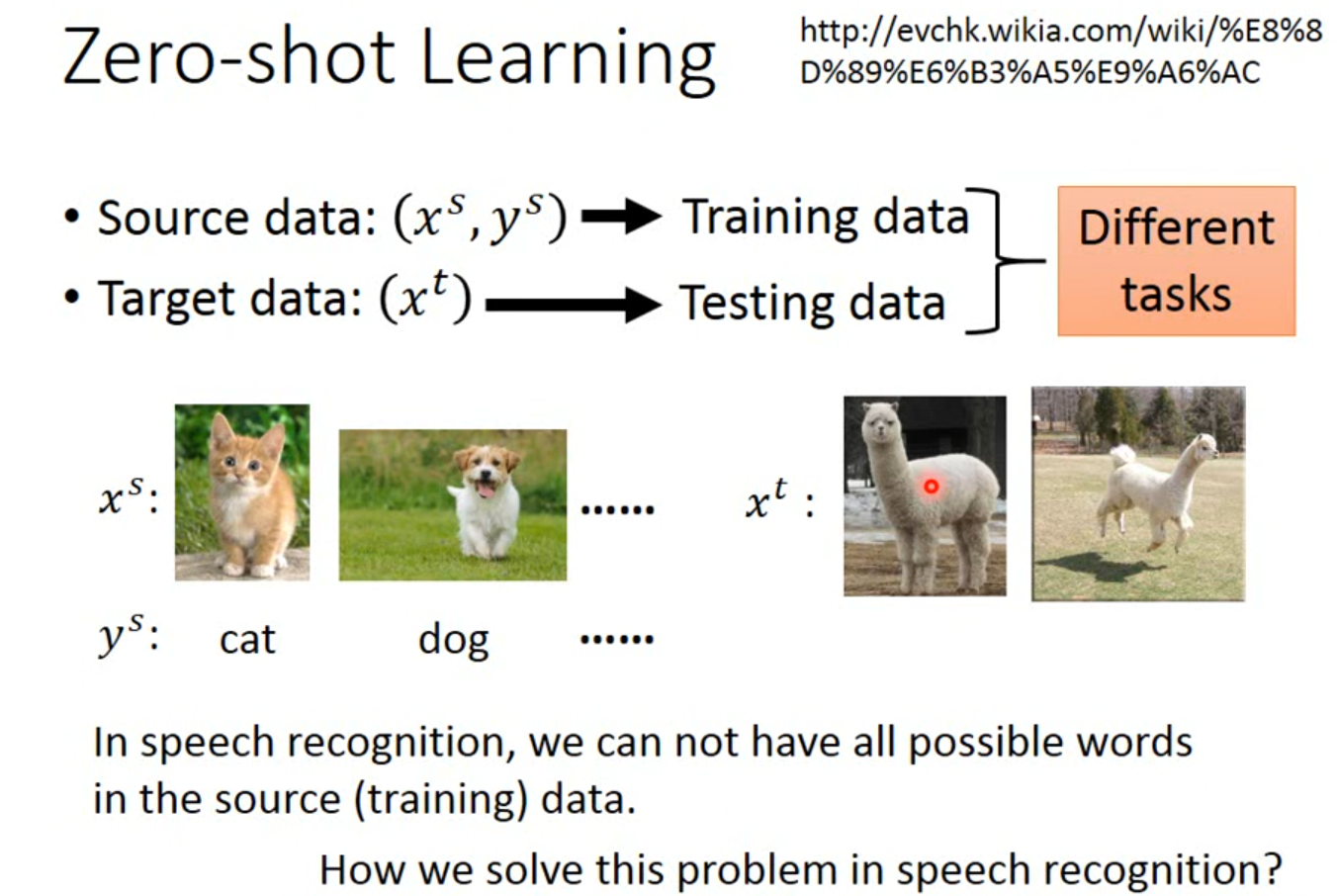
zero-shot learning
与上面的类似,但有不一样的是,source data和target data的任务是不一样的
source data从来没有出现过target data的内容
语音识别常见
解决思路是不去辨认一段声音属于什么word,而是辨认属于哪个phoneme
再建立phoneme和对应的表,查表即可
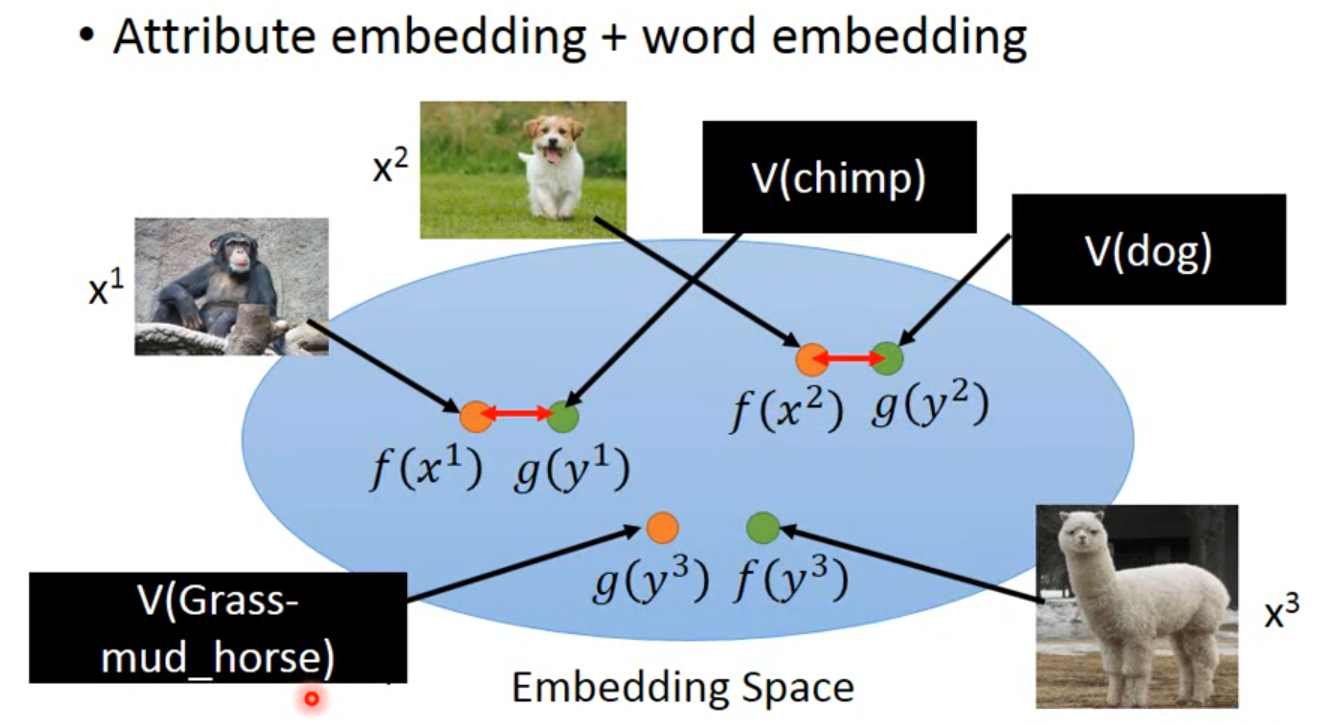
对于CV,可以建一个database,通过总结每个class的attributes的特点来判断
在training时候,建立class与attributes的对应
testing时,根据网络提取的attributes的特点查表,得到对应的class,找到最接近的
感觉CLIP的思想与这个类似
把图片用 $f$ 映射到一个特征空间,attributes通过 $g$ 映射到另一个特征空间,使得$f(x)$和$g(x)$越接近越好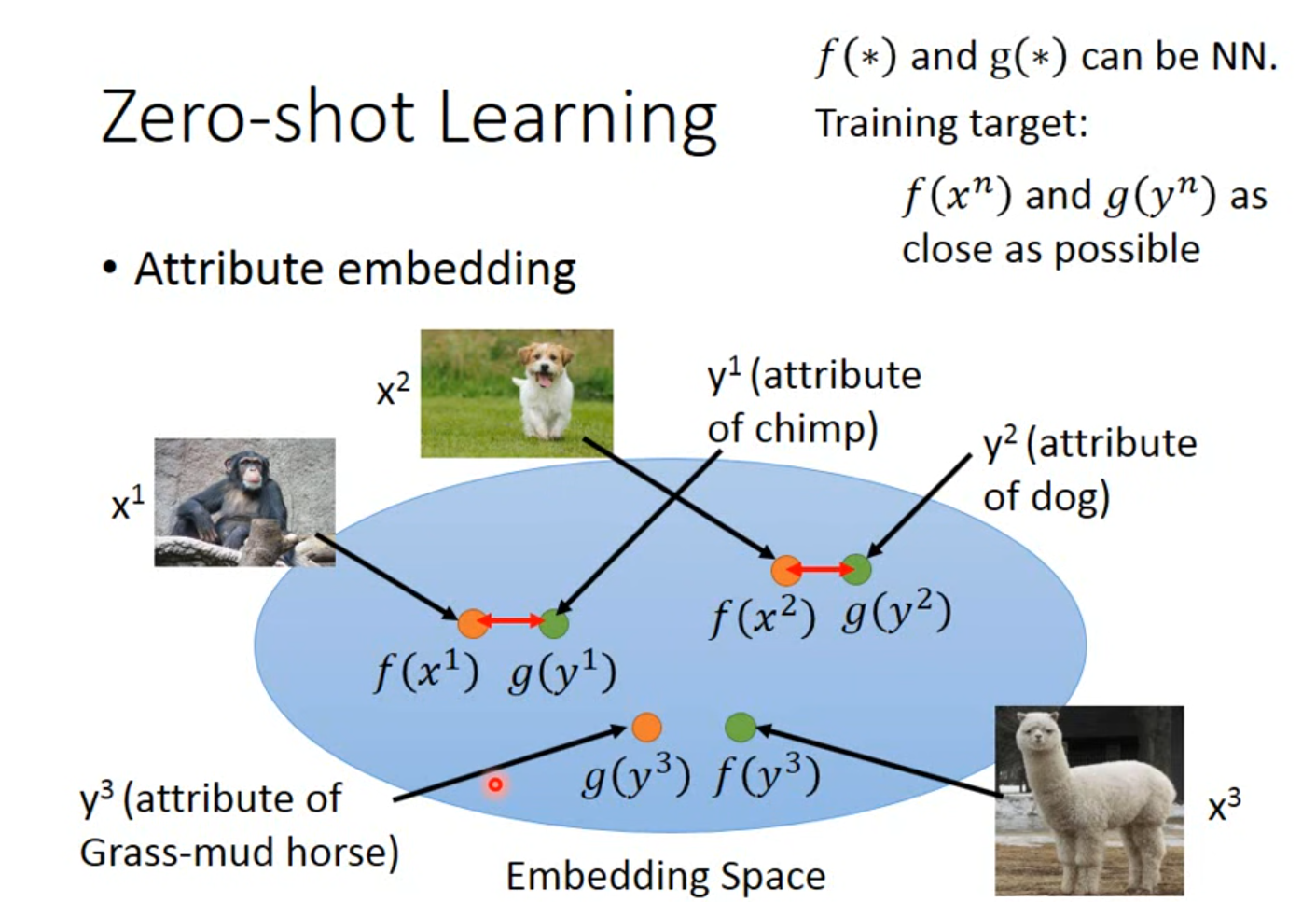
[!question] 如果没有database?
使用word2vec,把attributes用word2vec代替
损失函数
需要同时考虑到:
- 同一个配对,越接近越好
- 不同的配对,越远离越好
因此,这里的loss不能用原来的MSE,需要进行改正:
$$
f^*,g^* = arg \min_{f,g} \sum_{n} max(0, k - f(x^n) \cdot g(y^n)+\max_{m\neq n} f(x^n)g(y^m))
$$

- 混合word2vec
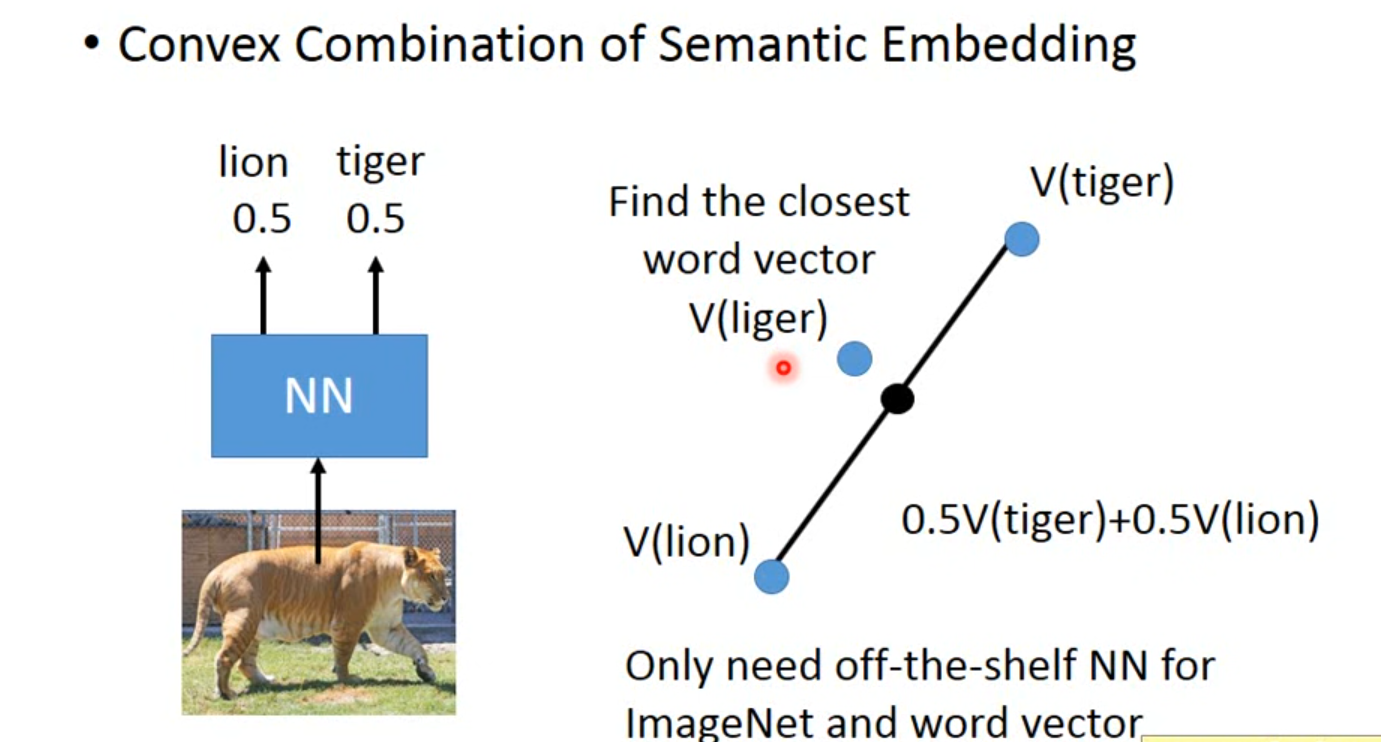
对不同语言丢到embedding后,表达相同意思的句子经投影的会聚集在一起
self-taught learning
source data unlabeled
target data labeled
与半监督学习不同,这里的 unlabeled data、source data与target data比较远