循环神经网络RNN
到目前为止我们默认数据都来自于某种分布, 并且所有样本都是独立同分布的 (independently and identically distributed,i.i.d.)。 然而,大多数的数据并非如此。例如,文章中的单词是按顺序写的,如果顺序被随机地重排,就很难理解文章原始的意思。同样,视频中的图像帧、对话中的音频信号以及网站上的浏览行为都是有顺序的。 因此,针对此类数据而设计特定模型,可能效果会更好。
另一个问题来自这样一个事实: 我们不仅仅可以接收一个序列作为输入,而是还可能期望继续猜测这个序列的后续。例如,一个任务可以是继续预测2,4,6,8,10,…。这在时间序列分析中是相当常见的,可以用来预测股市的波动、患者的体温曲线或者赛车所需的加速度。 同理,我们需要能够处理这些数据的特定模型。
简言之,如果说卷积神经网络可以有效地处理空间信息,那么本章的 循环神经网络 (recurrent neural network,RNN)则可以更好地处理序列信息。 循环神经网络通过引入状态变量存储过去的信息和当前的输入,从而可以确定当前的输出。
基本介绍
为了让神经网络有记忆力,能够对一段长序列进行处理
前馈神经网络只能针对单个向量处理,因此对于同一个输入会得到同一个输出,但却没有考虑前面的输入对当前的时刻带来的影响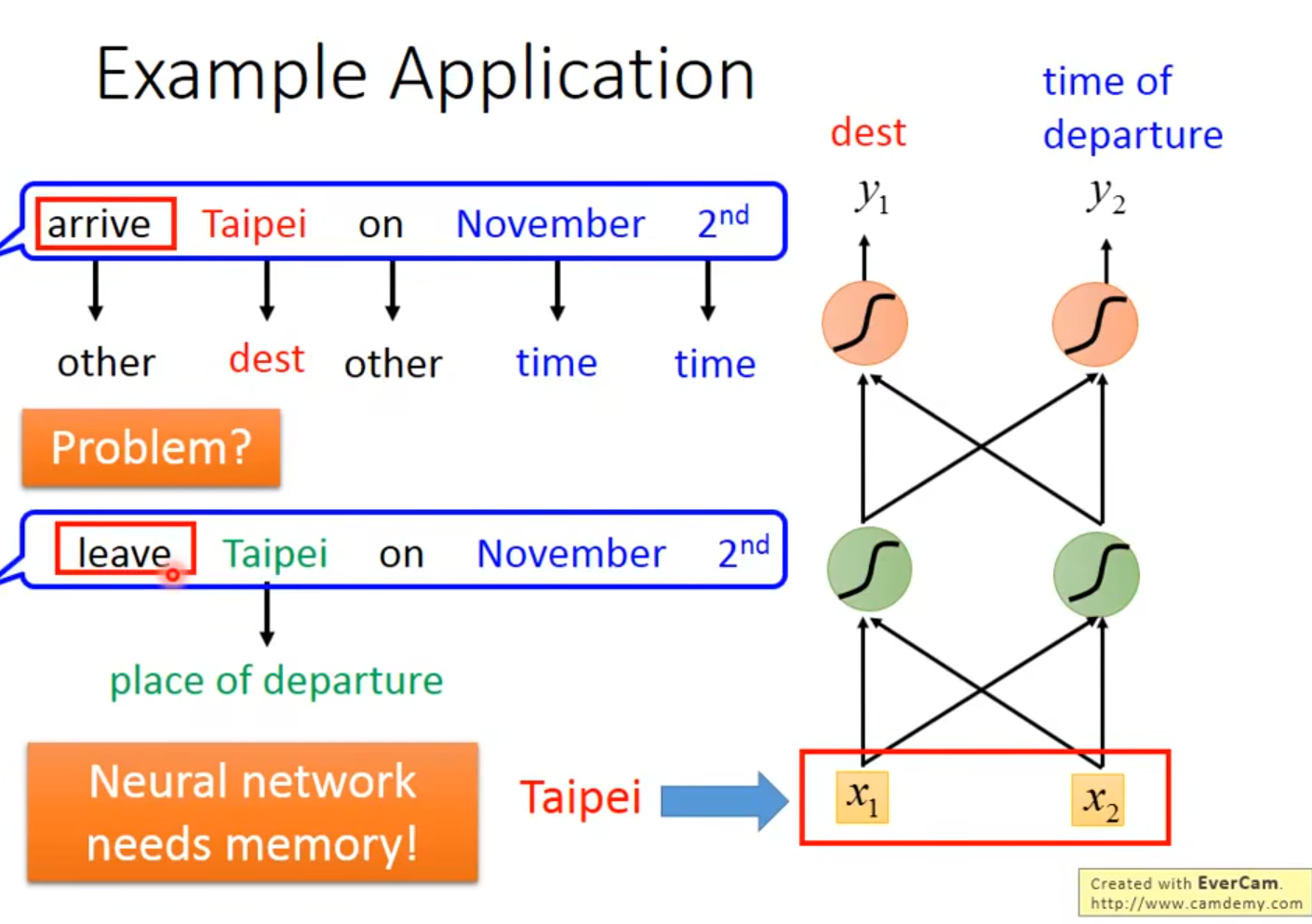
在 RNN 里面,每一次隐藏层的神经元产生输出的时候,该输出会被存到记忆元(memory cell),图中的蓝色方块表示记忆元。下一次有输入时,这些神经元不仅会考虑输入 $x_1$, $x_2$,还会考虑存到记忆元里的值。除了 $x_1$, $x_2$,存在记忆元里的值 $a_1$, $a_2$ 也会影响神经网络的输出。
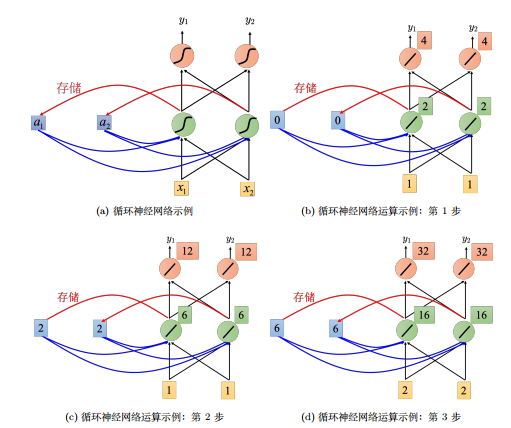
发现即使是对于相同的输入,由于有隐状态的存在,会使得输出也是不同的
有了记忆元以后,输入同一个单词,希望输出不同的问题就有可能被解决。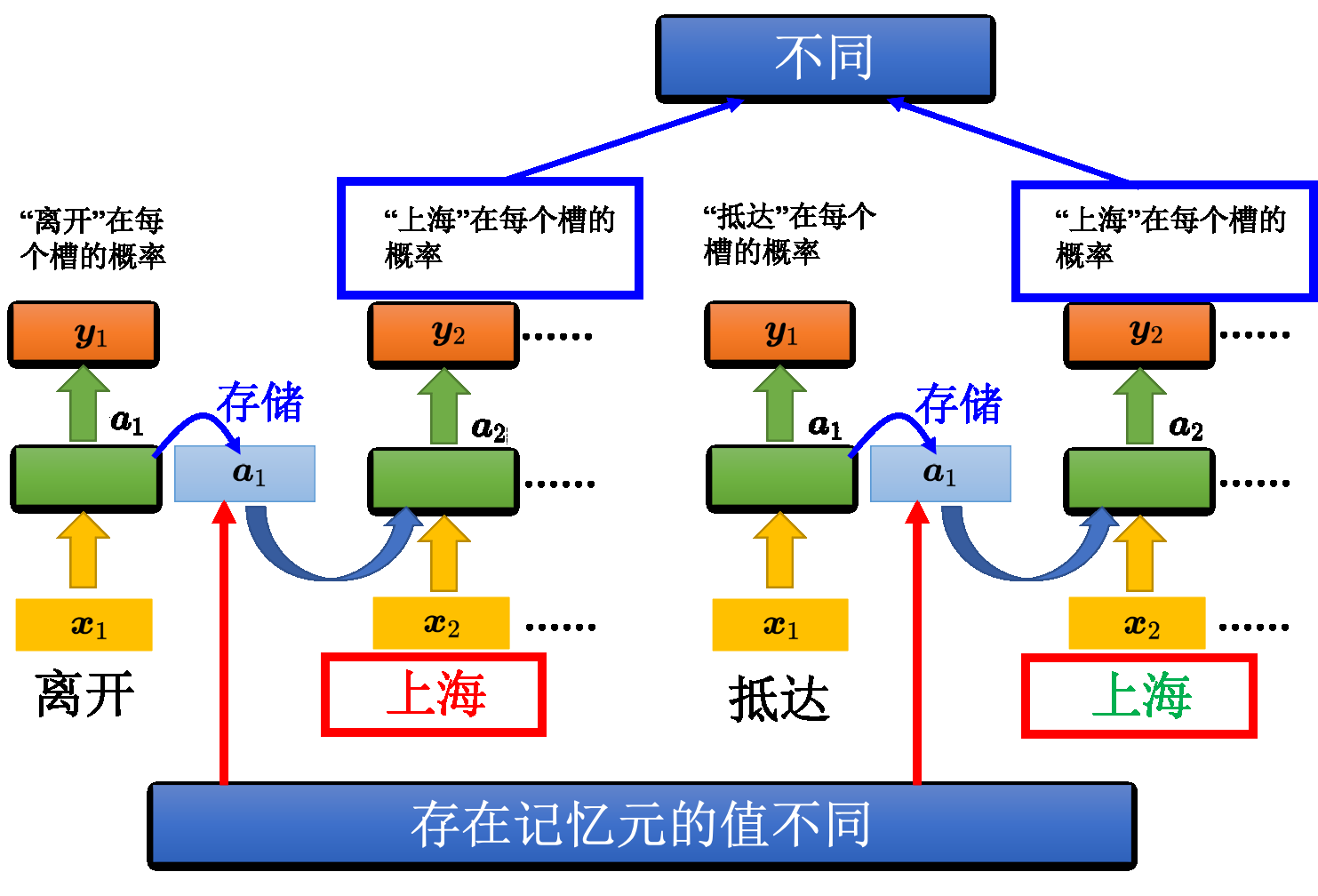
数学表达
RNN的基本单元与传统的前馈神经网络类似,但其隐藏层会在每一个时间步(time step)将当前输入和前一个时间步的隐藏状态结合起来。具体来说,RNN 在每一个时间步t的隐藏状态$ℎ_t$是由当前输入$x_t$和前一个时间步的隐藏状态$ℎ_{t−1}$共同决定的
$$
h_{t} = \sigma(W_{h} \cdot h_{t-1} + W_{x} \cdot x_{t} + b)
$$
- $h_{t}$时间步$t$的隐藏状态
- $x_{t}$ 为时间步 $t$ 的输入
- $W_{h}$和$W_{x}$是权重矩阵
- $b$是偏置
- $\sigma$是激活函数(如tanh或ReLU)

最终的输出公式:
$$
y_{t} = g(W_{y} h_{t}+c)
$$
其他RNN
之前提到的 RNN 只有一个隐藏层,但 RNN 也可以是深层的。比如把 $x_t$ 丢进去之后,它可以通过一个隐藏层,再通过第二个隐藏层,以此类推 (通过很多的隐藏层) 才得到最后的输出。每一个隐藏层的输出都会被存在记忆元里面,在下一个时间点的时候,每一个隐藏层会把前一个时间点存的值再读出来,以此类推最后得到输出,这个过程会一直持续下去。
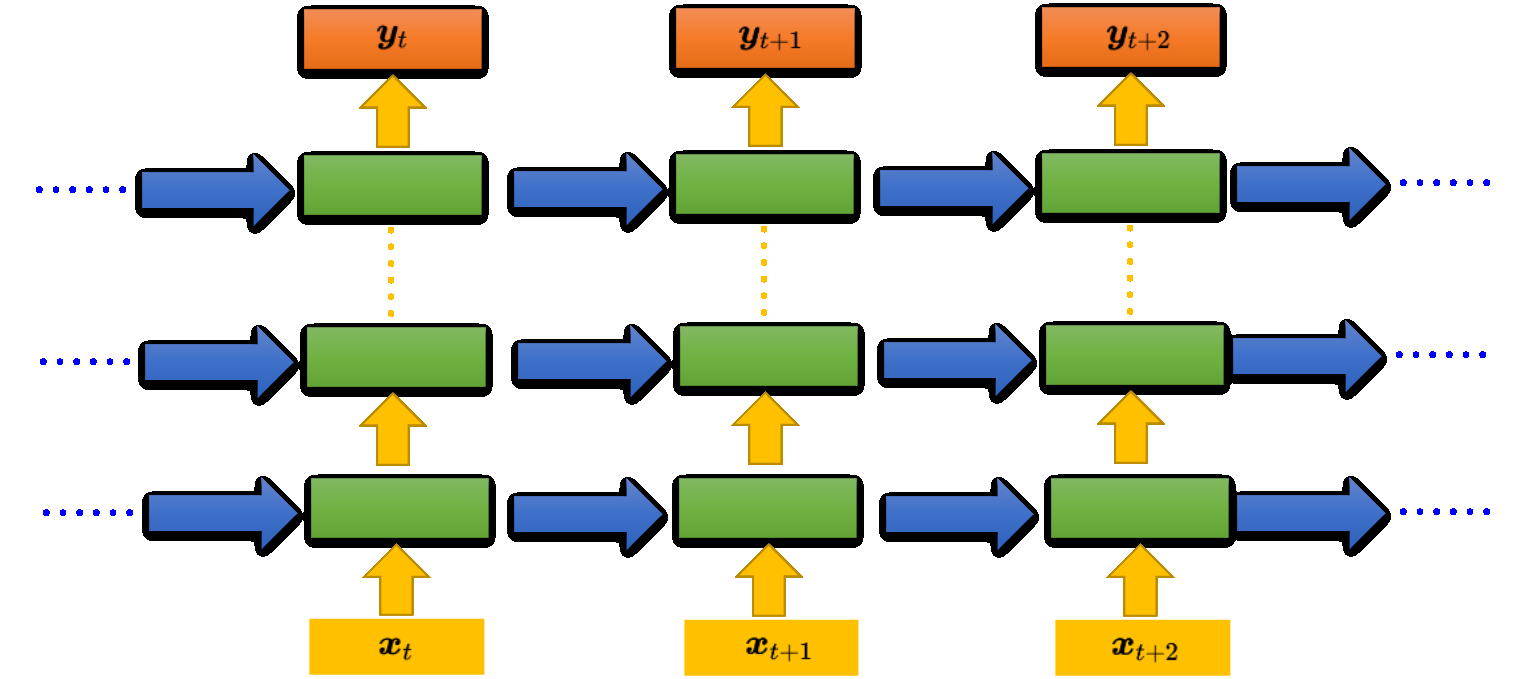
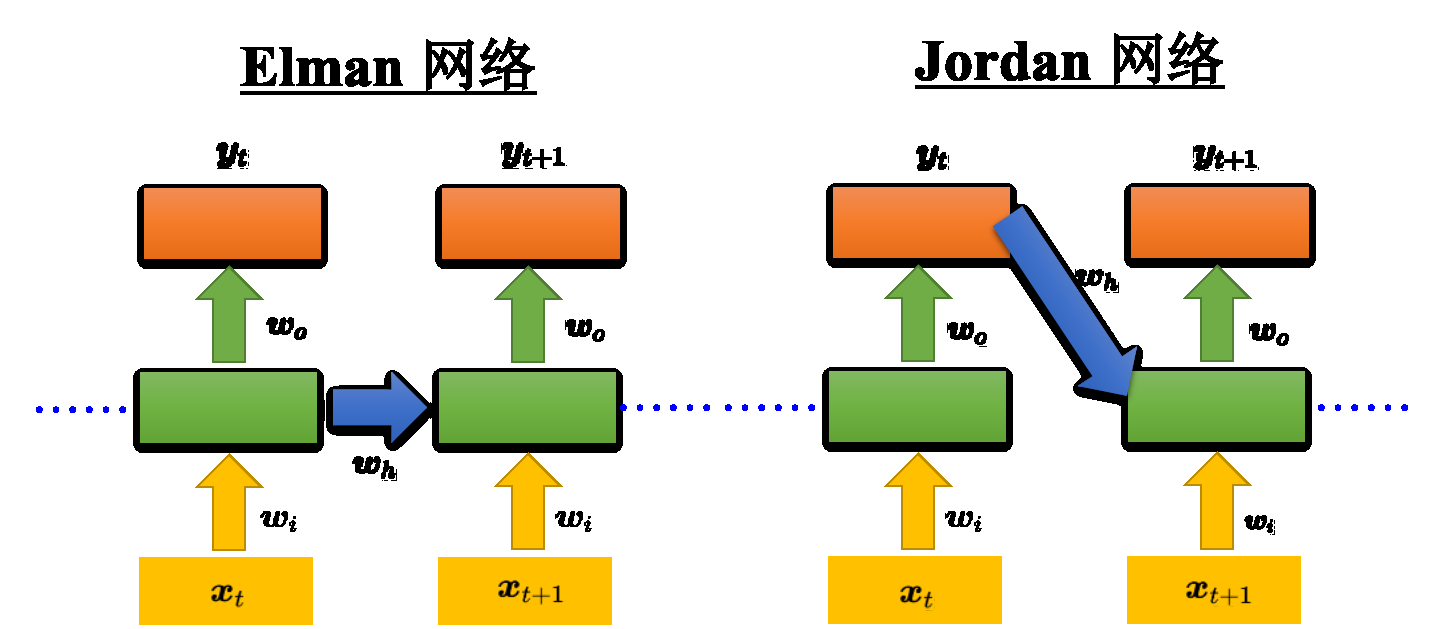
Elman & Jordan
Elman: 把隐藏层的值存起来,下一个时间点读出来
Jordan:存的是整个网络输出的值,会把输出值在下一个时间点读进来,并把输出都存到记忆元里
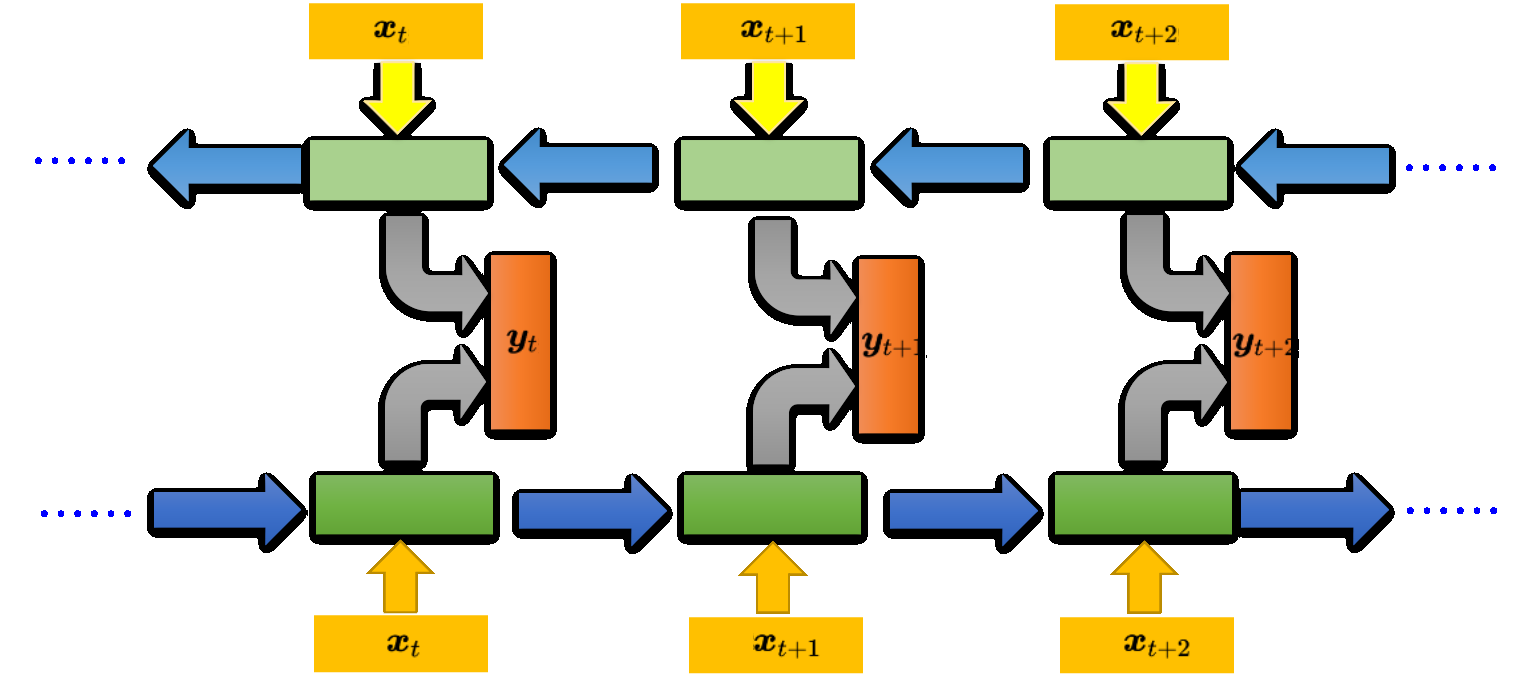
双向
网络不只是看过 $x_1$, 到 $x_{t+1}$ 所有的输入,它也看了从句尾到 $x_{t+1}$ 的输入。网络就等于整个输入的序列。假设考虑的是槽填充,网络就等于看了整个句子后,才决定每一个单词的槽,这样会比看句子的一半还要得到更好的性能。
RNN的梯度计算
随时间反向传播
在RNN中,参数的更新通过反向传播算法进行,具体是在时间维度上展开的反向传播,称为“时间反向传播”(BPTT)。与标准的反向传播不同,BPTT需要处理RNN的循环结构,即在多个时间步之间传播误差。
BPTT的基本步骤包括:
前向传播:
在前向传播过程中,从 $t = 1$ 到 $t = T$ 按顺序计算隐状态和输出。误差计算:
对于每个时间步 $t$,计算输出层的误差 $\delta_t$:
$$
\delta_t = \frac{\partial L}{\partial \mathbf{y}_t} \cdot g’(\mathbf{y}_t)
$$
其中,$L$ 是损失函数,$g’(\mathbf{y}_t)$ 是输出激活函数的导数。$\dfrac{\partial y_t}{\partial L}$ 是损失函数对输出的梯度。$g’(\mathbf{y}_t)$ 是输出激活函数的导数(如果使用softmax激活函数,通常是一个雅可比矩阵)。反向传播误差到隐状态:
接着,将误差从输出层传递到隐状态层,计算隐状态误差 $\delta_h$:$$
\delta_h = \frac{\partial L}{\partial \mathbf{h}_t} = \delta_t \cdot W_y^T \cdot f’(\mathbf{h}_t)
$$
其中,$f’(\mathbf{h}t)$ 是隐状态激活函数的导数。$\delta{t}$ 是输出误差,$W_y^T$ 是输出层到隐状态的权重矩阵的转置。时间步之间误差的传播:
由于RNN的隐状态依赖于前一时间步的隐状态,误差需要反向传播回多个时间步。对于每个时间步 $t$,计算误差在前一时间步的传播:
$$
\delta_{h_{t-1}} = \delta_h \cdot W_h^T \cdot f’(\mathbf{h}_{t-1})
$$
这种方式从后往前(从 $T$ 到 $1$)递归地传递误差,直到到达序列的开始。梯度计算:
一旦计算了误差,使用链式法则计算各个参数的梯度:- 对于 $W_h$,梯度计算为:
$$
\frac{\partial L}{\partial W_h} = \sum_{t=1}^T \delta_{h_{t}} \cdot \mathbf{h}{t-1}^T
$$
这个梯度的含义是:每个时间步的误差 $\delta{h_t}$ 乘以前一个时间步的隐状态 $\mathbf{h}_{t-1}$,然后在所有时间步上求和,得到参数 $W_h$ 的梯度。 - 对于 $W_x$,梯度计算为:
$$
\frac{\partial L}{\partial W_x} = \sum_{t=1}^T \delta_{h_{t}} \cdot \mathbf{x}_t^T
$$ - 对于 $W_y$,梯度计算为:
$$
\frac{\partial L}{\partial W_y} = \sum_{t=1}^T \delta_{t} \cdot \mathbf{h}_t^T
$$ - 对于偏置项 $b$ 和 $c$,梯度计算为:
$$
\frac{\partial L}{\partial b} = \sum_{t=1}^T \delta_{h_{t}}
$$
$$
\frac{\partial L}{\partial c} = \sum_{t=1}^T \delta_{t}
$$
- 对于 $W_h$,梯度计算为:
参数更新:
使用梯度下降或其他优化算法(如Adam)更新模型的参数:
$$
W_h = W_h - \eta \cdot \frac{\partial L}{\partial W_h}
$$
$$
W_x = W_x - \eta \cdot \frac{\partial L}{\partial W_x}
$$
$$
W_y = W_y - \eta \cdot \frac{\partial L}{\partial W_y}
$$
$$
b = b - \eta \cdot \frac{\partial L}{\partial b}
$$
$$
c = c - \eta \cdot \frac{\partial L}{\partial c}
$$
其中,$\eta$ 是学习率。
总结
- RNN的核心:通过隐状态的循环连接处理序列数据,每个时间步的输出依赖于当前输入和前一时间步的隐状态。
- BPTT:是RNN中用于训练的反向传播算法,通过反向传播误差在时间步之间传播,计算每个时间步的梯度,最终更新网络参数。
训练问题
RNN 的训练是比较困难的,一般而言,在做训练的时候,期待学习曲线是像蓝色这条线,这边的纵轴是总损失(total loss),横轴是回合的数量,我们会希望随着回合的数量越来越多,随着参数不断的更新,损失会慢慢地下降,最后趋向收敛。但是不幸的是,在训练循环神经网络的时候,有时候会看到绿色这条线。
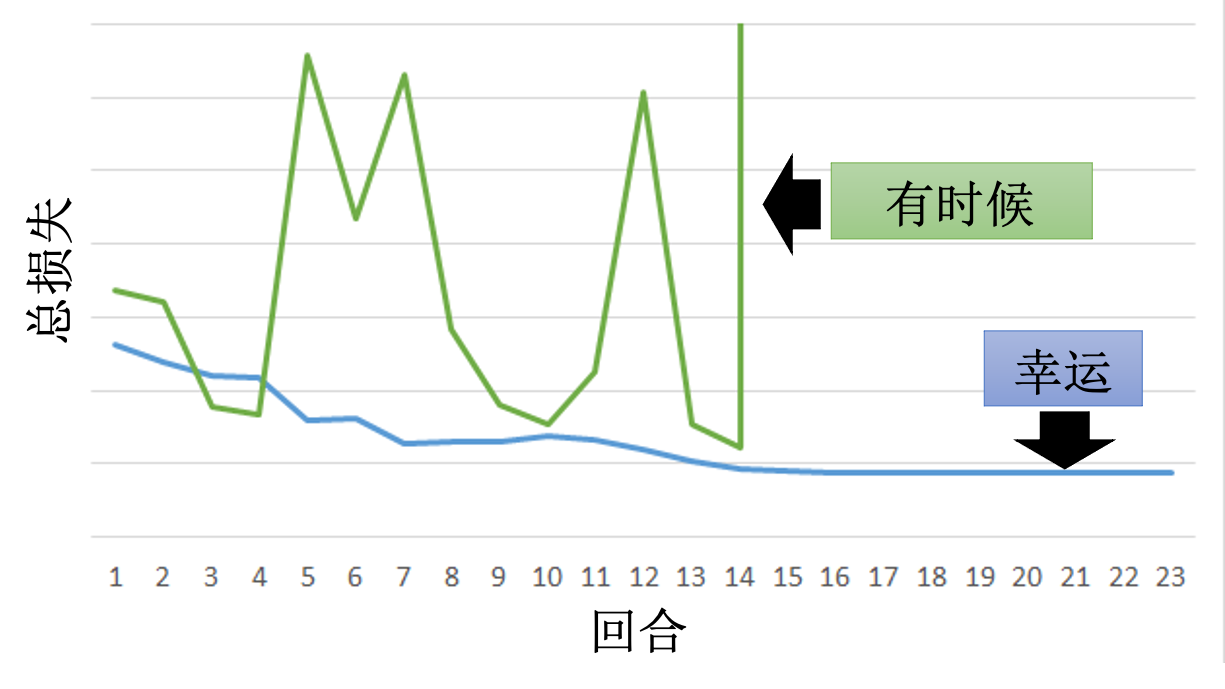
出现这种状况的原因是RNN的误差表面有的地方非常平坦,但有的地方又非常陡峭,可能会导致损失快速震荡以及梯度消失问题。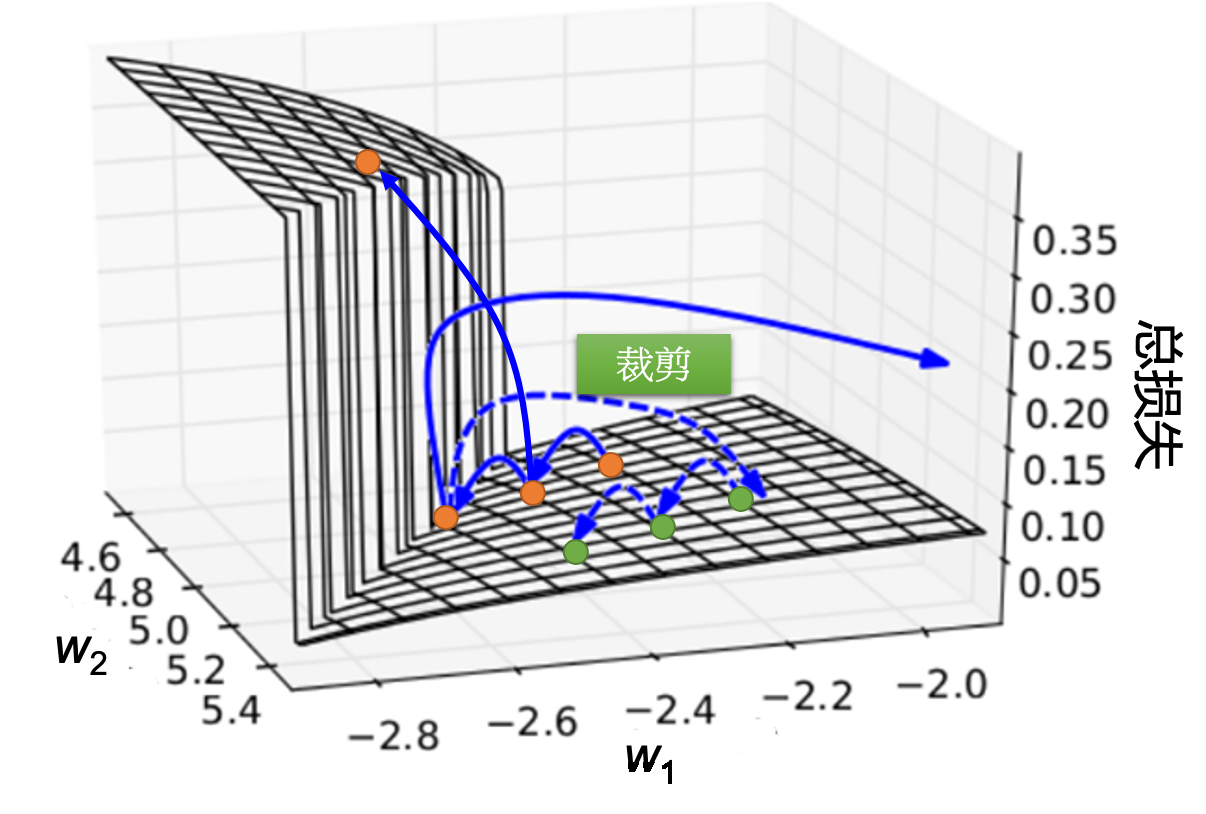
- 梯度消失:在长时间序列的训练过程中,通过反向传播计算梯度时,误差在传播回前面时间步时会逐渐变小。如果RNN中使用的是tanh或sigmoid等激活函数,它们的梯度会在某些情况下变得非常小(尤其是在极端输入的情况下)。当误差被反向传播到很远的时间步时,梯度会变得几乎为零,这导致网络无法有效地学习长期依赖关系。
- 具体来说,假设在每个时间步 ttt,隐状态 $\mathbf{h}t$ 的更新包含了一个梯度乘积 $\prod{i=1}^t W_{h}$ (每一步都包含一个与权重相关的梯度)。当该梯度过小时,整个梯度也会被缩小,导致远程时间步的信息几乎无法传递。
- 梯度爆炸:每次梯度传播时,如果权重矩阵的值过大,就可能导致梯度变得过大,进而导致数值不稳定,甚至出现溢出。
- 这种情况出现的原因不是因为激活函数,而是由于同样的权重在不同的时间点被反复使用。
现代循环神经网络
我们可能会遇到这样的情况:
- 早期观测值对预测所有未来观测值具有非常重要的意义。
- 考虑一个极端情况,其中第一个观测值包含一个校验和,目标是在序列的末尾辨别校验和是否正确。在这种情况下,第一个词元的影响至关重要。我们希望有某些机制能够在一个记忆元里存储重要的早期信息。如果没有这样的机制,我们将不得不给这个观测值指定一个非常大的梯度,因为它会影响所有后续的观测值。
- 一些词元没有相关的观测值。
- 例如,在对网页内容进行情感分析时,可能有一些辅助HTML代码与网页传达的情绪无关。我们希望有一些机制来 跳过 隐状态表示中的此类词元。
- 序列的各个部分之间存在逻辑中断。
- 例如,书的章节之间可能会有过渡存在,或者证券的熊市和牛市之间可能会有过渡存在。 在这种情况下,最好有一种方法来 重置 我们的内部状态表示。
同时,考虑到上面提出的长程依赖问题,需要对梯度进行处理
长短期记忆网络
[!info] Lee 在这部分使用的符号表示比较特别(混乱),下面有其他的表示方式
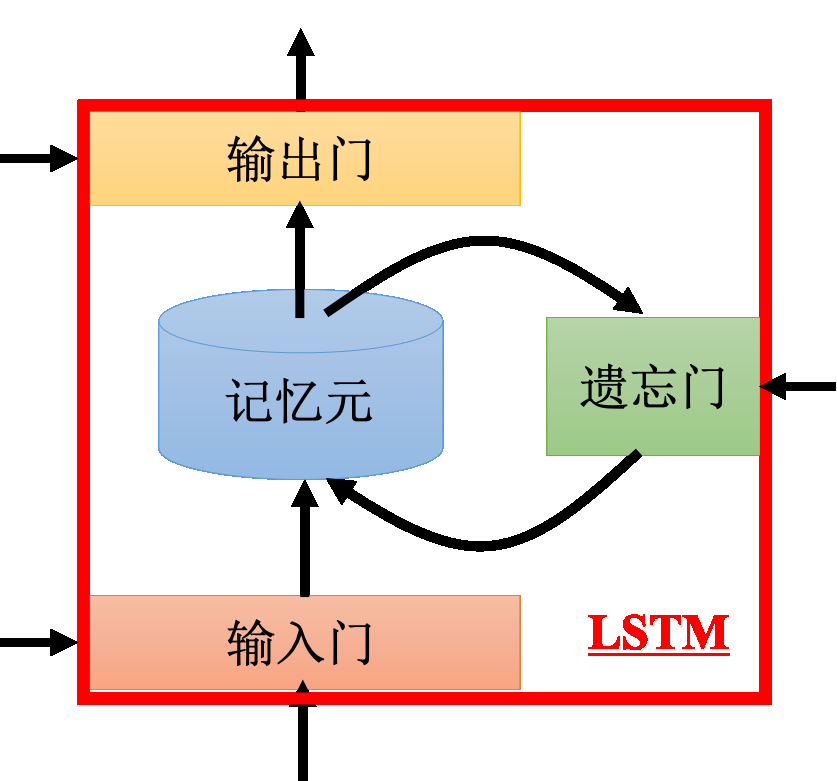
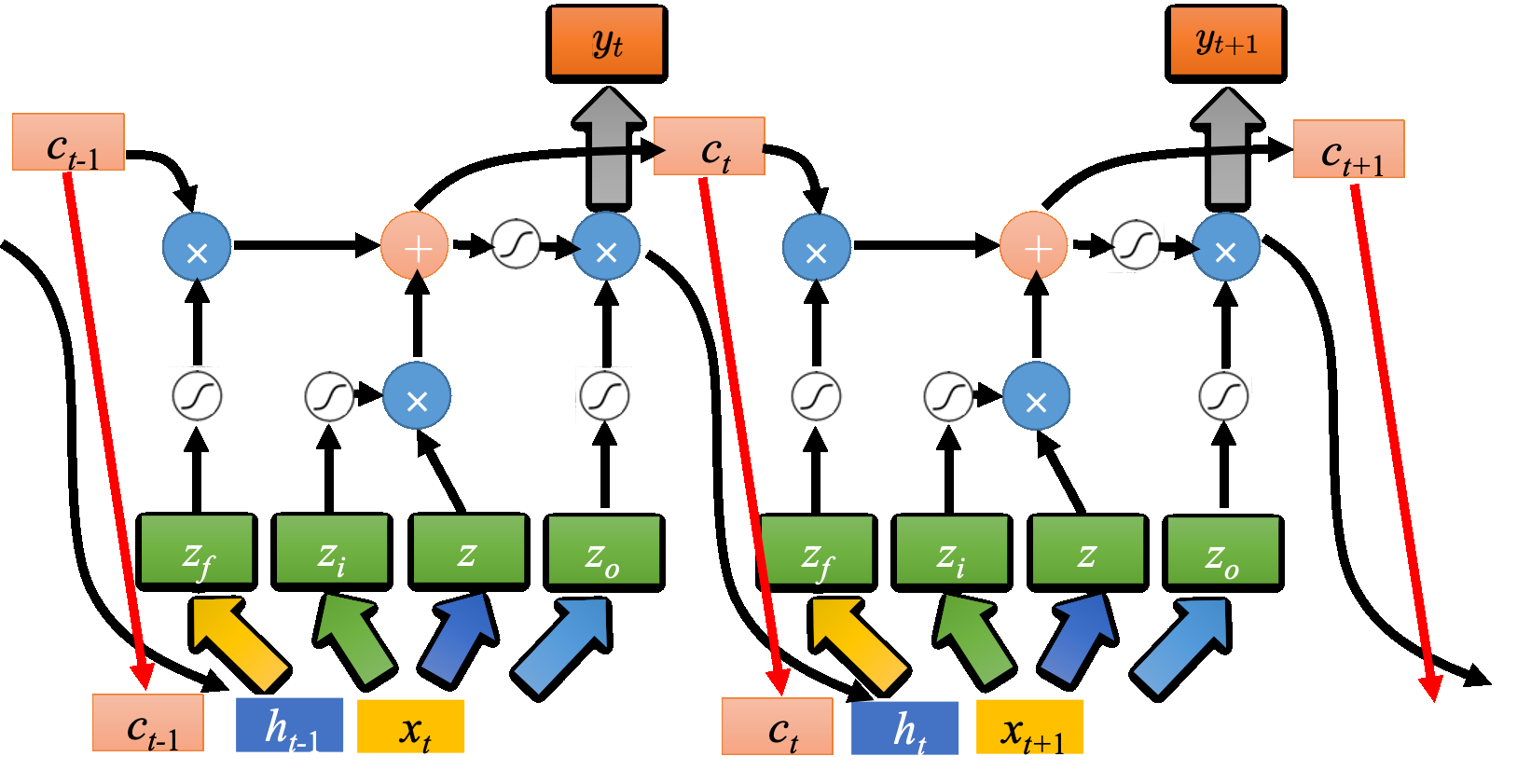
4个输入,1个输出,LSTM 通过引入“记忆单元”(cell state)和“门机制”(gates)来更好地管理信息的流动。
三个门
- 输入门:输入门要被打开的时候,才能把值写到记忆元里面。如果把这个关起来的话,就没有办法把值写进去。
- 输出门:会决定外界其他的神经元能否从这个记忆元里面把值读出来。把输出门关闭的时候是没有办法把值读出来,输出门打开的时候才可以把值读出来。
- 遗忘门:决定什么时候记忆元要把过去记得的东西忘掉。
“-”应该在 short-term 中间,是长时间的短期记忆。之前的循环神经网络,它的记忆元在每一个时间点都会被洗掉,只要有新的输入进来,每一个时间点都会把记忆元洗掉,所以的短期是非常短的,但如果是长时间的短期记忆元,它记得会比较久一点,只要遗忘门不要决定要忘记,它的值就会被存起来。
网络自己会学到什么时候开门和关门
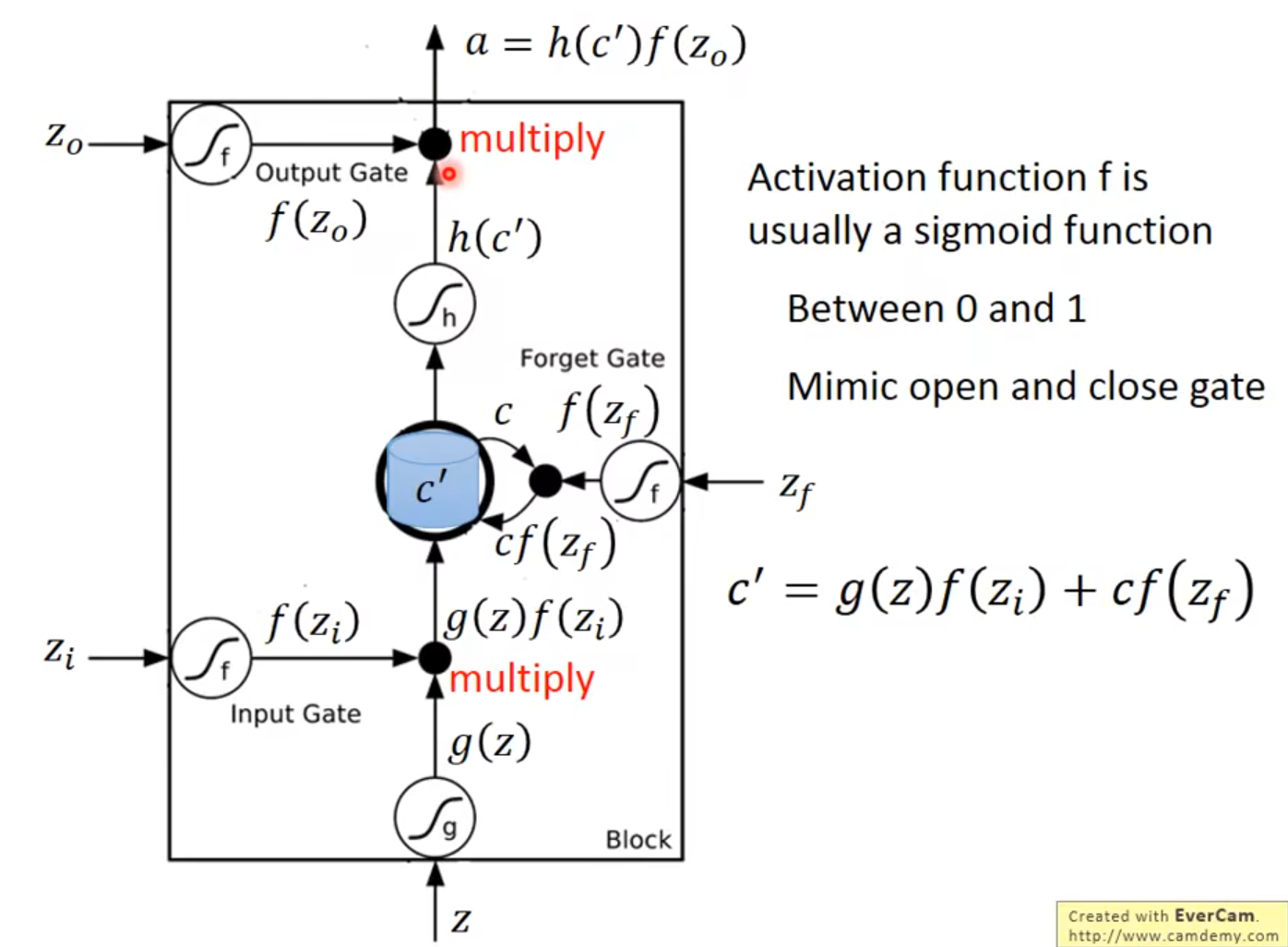
记忆元计算公式
$$
c’=g(z)f(z_{i})+cf(z_{f})
$$
也有写作
$$
c_{t} = \tilde{c_{t}} \odot i_{t} + c_{t-1} \odot f_{t}
$$
其中,$\odot$ 是按元素乘
假设:
- 存到单元的输入叫做 $z$ (这里是因为有可能前面还过了LSTM层,所以记成 $z$,但是一般也可以直接写成 $\mathbf{x_{t}}$,这里这么写是因为把 $\mathbf{x_{t}}$ 进行了拆分:$\mathbf{x}{t} = [z, z{i}, z_{f}, z_{o}]$)
- 操控输入门的信号为 $z_i$ ,对应激活后的结果是$f(z_{i})$(也可写作$i_{t}$,$i_{t} = \sigma (W_{i} \cdot [\mathbf{h}{t-1},\mathbf{x{t}}] + b_{i}$)
- 操控遗忘门的信号为 $z_f$ ,对应激活后的结果是$f(z_{f})$(也可写作$f_{t}$,$f_{t} = \sigma(W_{f} \cdot [\mathbf{h_{t-1}, \mathbf{x}{t}}] + b{f})$)
- 操控输出门为 $z_o$,对应激活后的结果为 $f(o_{t})$(也可写作$o_{t}$,$o_{t} = \sigma(W_{o} \cdot [\mathbf{h}{t-1}, \mathbf{x{t}}] + b_{o})$)
- 输出记为 $a$,即隐状态$\mathbf{h_{t}}$,$\mathbf{h_{t}} = o_{t} \odot \tanh(c_{t})$
- 单元初始值 $c$,即 $c_{t-1}$
- 激活后的候选状态即为 $g(z)$,也可写作$\tilde{c_{t}}$,即为激活后的新信息,$\tilde{c_{t}} = \tanh(W_{c} \mathbf{x}{t}+U{c}\mathbf{h}{t-1}+b{c})$
把 $z$ 通过激活函数得到 $g(z)$,$z_i$ 通过另外一个激活函数得到 $f(z_i)$ (激活函数通常会选择 sigmoid 函数,因为其值介在 0 到 1 之间的,这个 0 到 1 之间的值代表了这个门被打开的程度).如果 $f$ 的输出是 1,表示为被打开的状态,反之代表这个门是关起来的
接着把$g(z)$乘以$f(z_{i})$,得到$g(z)f(z_{i})$,遗忘门也通过sigmoid函数得到$f(z_{f})$,接下来相加得到上式。
遗忘门的开关是跟直觉是相反的,遗忘门打开的时候代表的是记得,关闭的时候代表的是遗忘。
计算输出:$c’$通过tanh得到$h(c’)$,将其乘以激活的$f(z_{o})$得到$a=h(c’)f(z_{o})$。输出门受$f(z_{o})$操控
示意图2: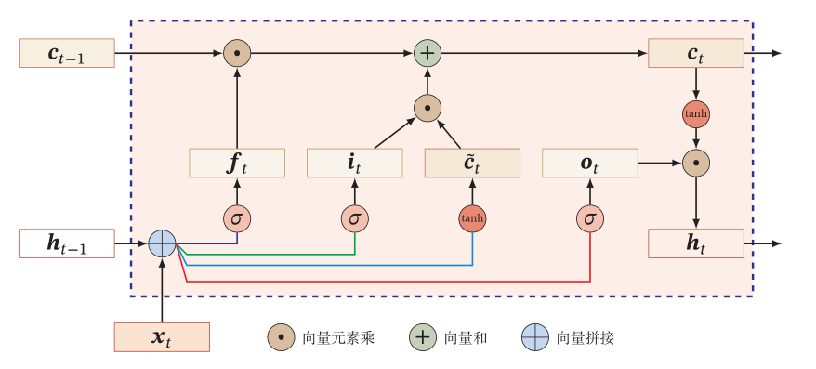
举例
网络里面只有一个 LSTM 的单元,输入都是三维的向量,输出都是一维的输出。这三维的向量跟输出还有记忆元的关系是这样的。假设 $x_2$ 的值是 1 时,$x_1$ 的就会被写到记忆元里;假设 $x_2$ 的值是-1 时,就会重置这个记忆元;假设 $x_3$ 的值为 1 时,才会把输出打开,才能看到输出,看到记忆元的数字。
于是更新过程如下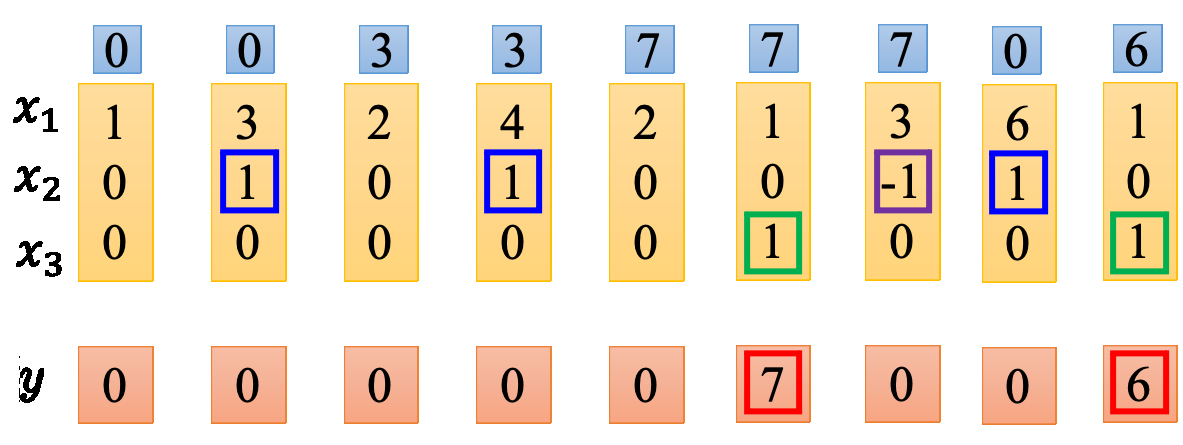
运算举例
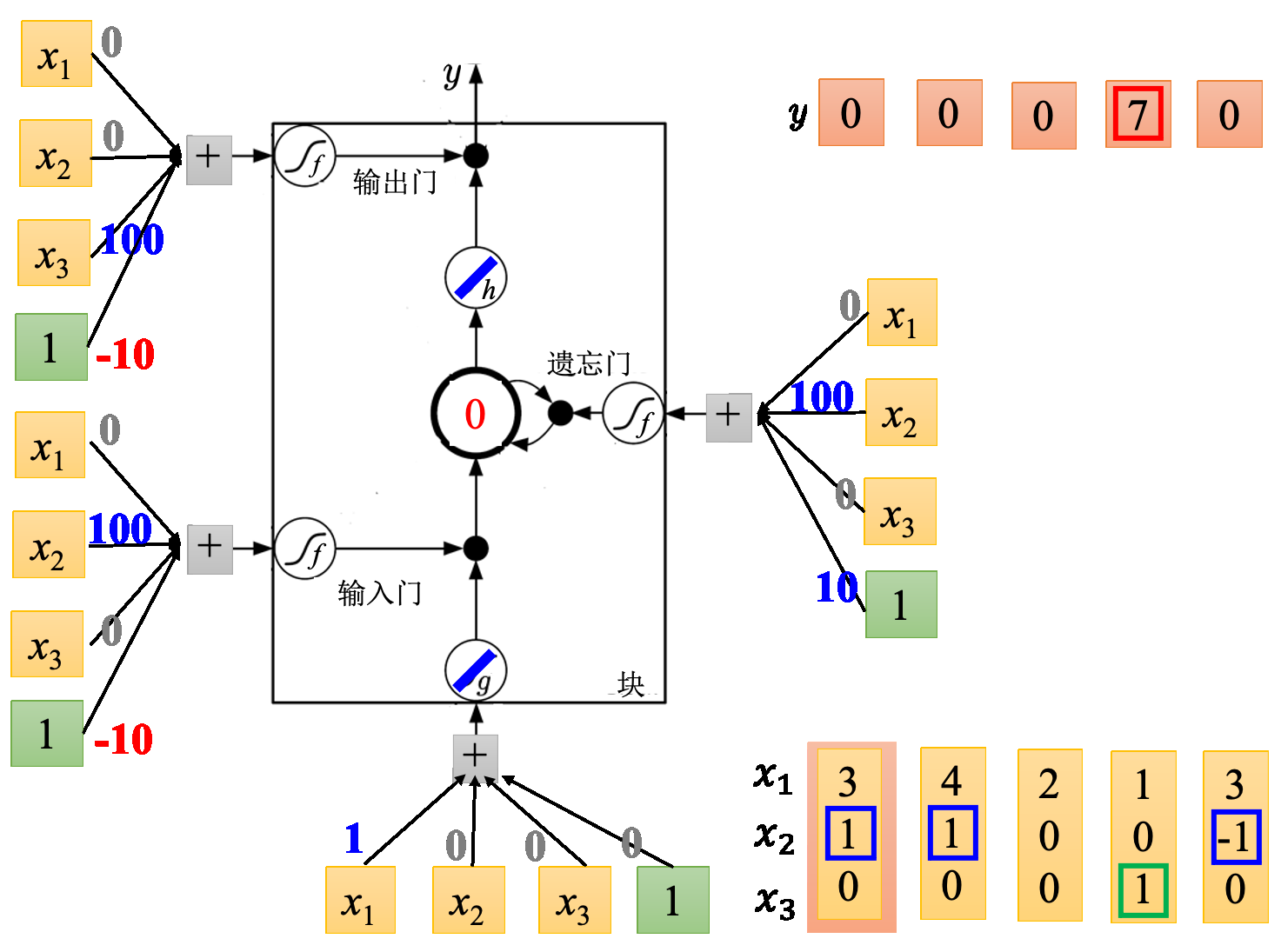
直接代入,发现输入门通常是关闭的,只有当$x_{2}$有大于1的值才会打开;遗忘门通常是打开的,只有$x_{2}$是个大的负值才会关闭;输出门通常关闭,只有$x_{3}$有大于1的值才会打开
LSTM网络原理
可以把LSTM想成一个神经元
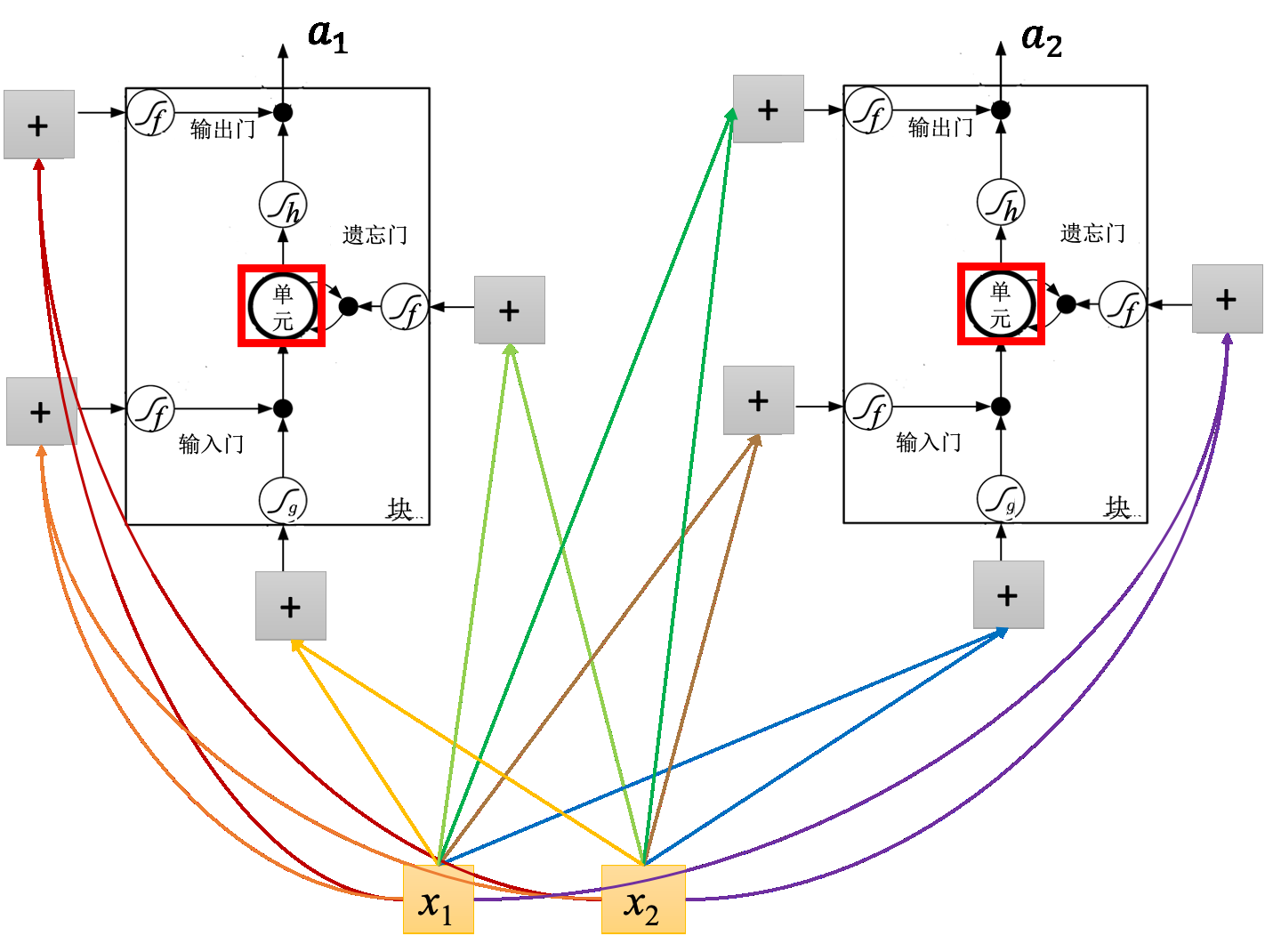
假设只有2个神经元,输入$x_{1},x_{2}$会乘以不同的权重当作输入,去控制输出门、输入门、底部输入和遗忘门。因此,假设用的神经元的数量跟 LSTM 是一样的,则 LSTM 需要的参数量是一般神经网络的四倍。
假设有一整排的 LSTM,这些 LSTM 里面的记忆元都存了一个值,把所有的值接起来就变成了向量,写为 $c_{t−1}$(一个值就代表一个维度)。现在在时间点 $t$,输入向量 $x_{t}$,经过矩阵乘法会变成$z,z_{i},z_{o},z_{f}$四个向量,向量维度与单元数量相同,随后将其作为输入,去操控所有的cell。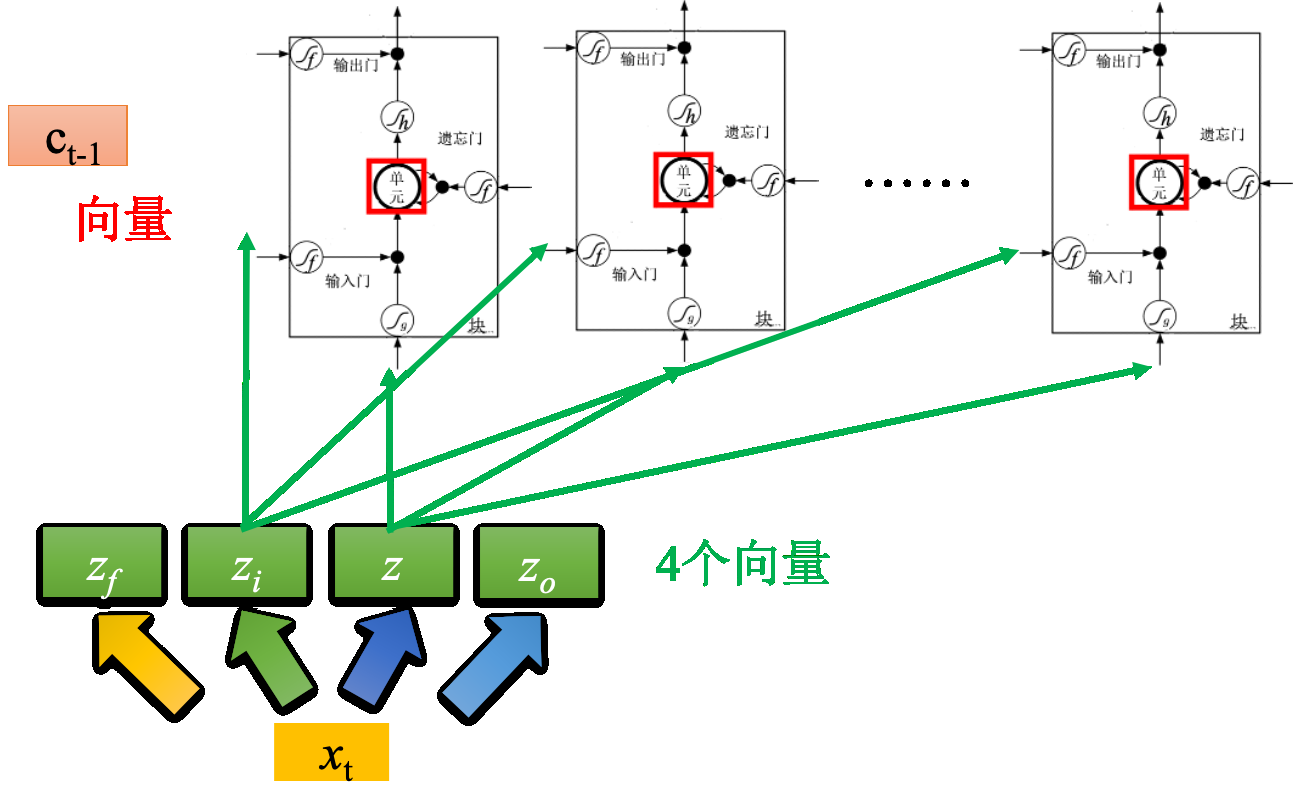
输入cell都是z的一个dimension,因此所有cell可以一起运算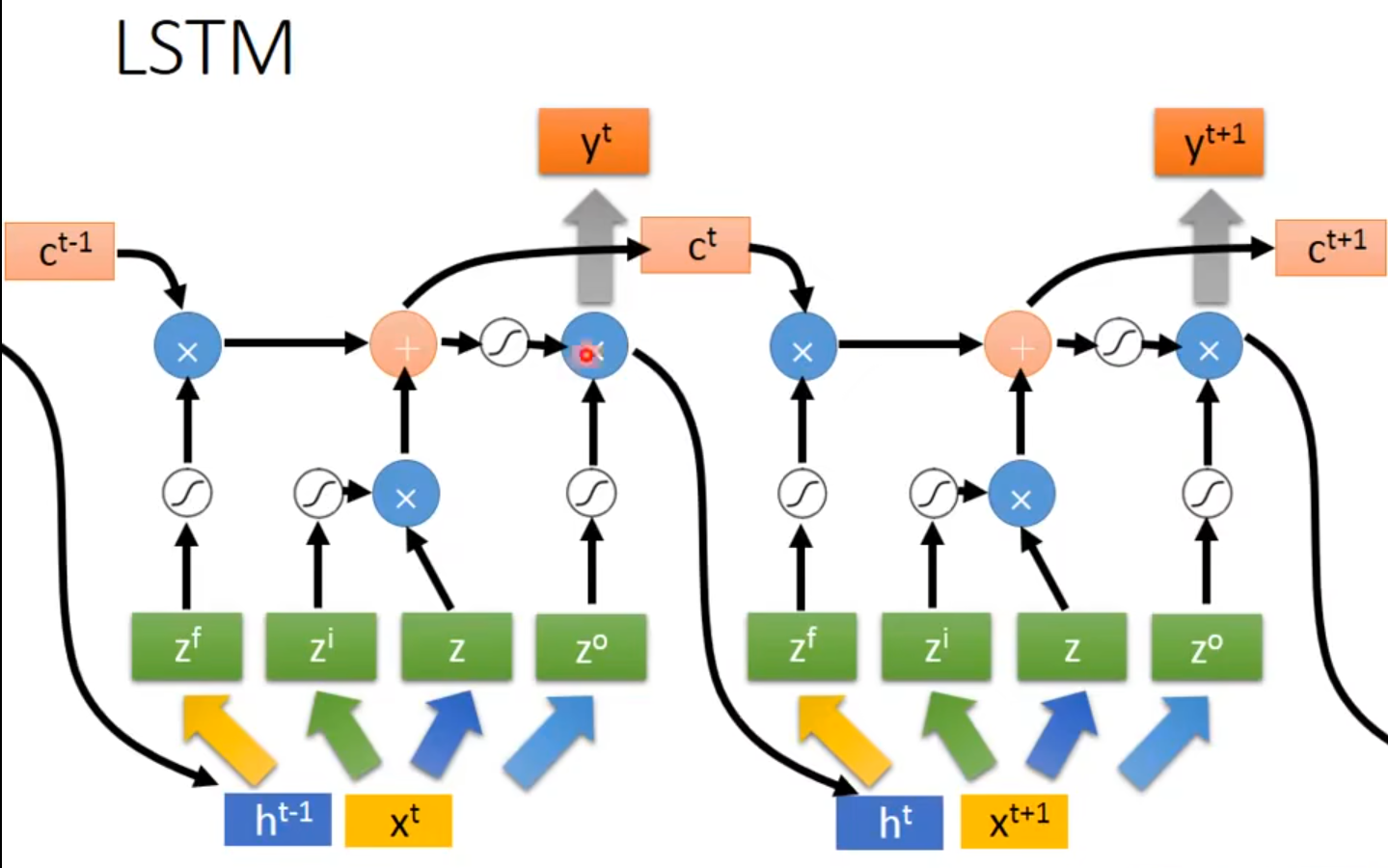
但还不是最后的LSTM,还需要加上上一时刻输出的值$h_{t}$和peephole连接,即存在记忆元里面的值$c_{t}$。先将3个向量并在一起执行不同的变换,得到4个不同的向量,之后再操控LSTM。
于是多层的LSTM: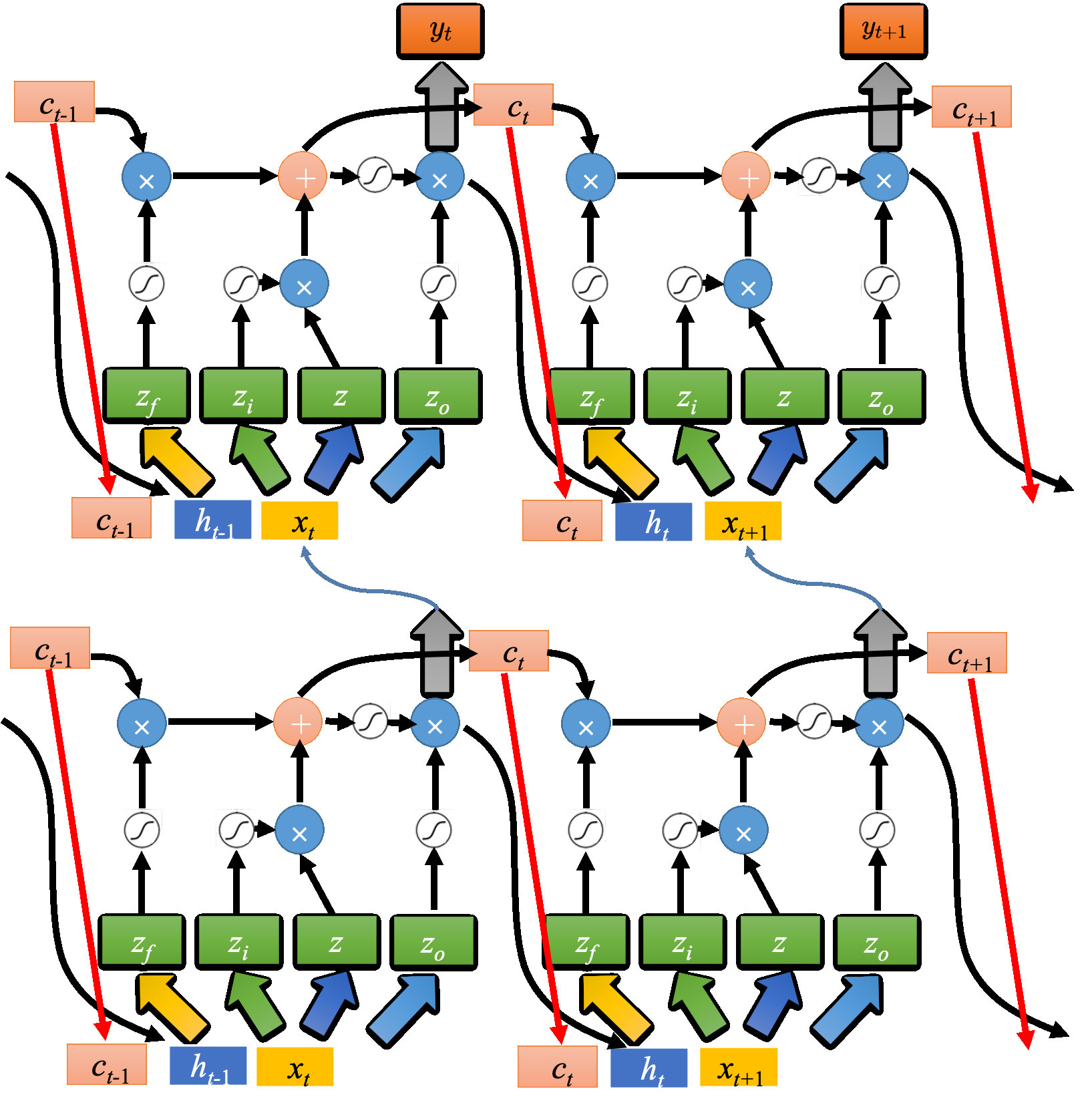
处理梯度问题
回到记忆单元更新的式子:
$$
c_{t} = f_{t} \odot c_{t-1} + i_{t} \odot \tilde{c_{t}}
$$
记忆单元状态的梯度传递:在 LSTM 中,记忆单元状态的更新涉及到加法操作,使得梯度在时间步之间的传递变为:
$$
\frac{\partial \mathcal{L}}{\partial c_{t-1}} = \frac{\partial \mathcal{L}}{\partial c_t} \cdot \frac{\partial c_t}{\partial c_{t-1}} = \frac{\partial \mathcal{L}}{\partial c_t} \cdot f_t
$$
$$
\frac{\partial \mathcal{L}}{\partial c_{t-k}} = \frac{\partial \mathcal{L}}{\partial c_t} \cdot \prod_{i=t-k+1}^{t} f_i
$$
这里的乘积$\prod_{i=t-k+1}^t f_{i}$中每个$f_{i}$的值都在 [0,1] 之间。如果所有的$f_{i}$都接近于1,梯度可以顺利传递;如果 $f_{i}$有一些接近0,会导致梯度快速衰减,从而避免梯度爆炸门控机制的设计:LSTM 的遗忘门、输入门和输出门是通过 sigmoid 函数来实现的,sigmoid 的输出范围是[0, 1]。这种门控机制可以灵活地控制信息流动,使得梯度在传播过程中不会出现极端的情况(如全是 0 或全是 1)
记忆单元状态的加法更新:LSTM 的记忆单元状态更新是通过加法操作,而不是乘法操作。加法操作在反向传播时,梯度不会像乘法那样呈指数级增长或衰减。这是 LSTM 相比于传统 RNN 的一个重要改进。
长短期记忆的平衡:LSTM 的设计初衷是平衡短期和长期记忆。遗忘门控制着旧信息的遗忘,输入门控制着新信息的记忆。通过这种平衡机制,LSTM 可以在处理长序列数据时,动态地选择保留或丢弃信息,从而在一定程度上缓解梯度消失或爆炸的问题。
[!info] 为什么Ilya说LSTM是一个旋转90度的ResNet?
这是Ilya在NIPS上的发言,虽然时间上ResNet比LSTM晚出,但当时应该没有人想到这两个网络之间存在的关联。也就是说,时间维度(LSTM)在一定程度上和深度是可以挂钩的。
我们考虑两个维度:网络深度和时间维度。网络深度指不同feature 存在于不同的layer然后在前向过程中不断地传到下一层的深度。时间维度指类似于 next word prediction 不断地通过过去的输出预测下一个词的时间步。
GRU 门控循环单元
[!info] 此处主要参考d2l
只有两个门,但性能差不多,且不太容易过拟合
门控循环单元与普通的循环神经网络之间的关键区别在于:前者支持隐状态的门控。这意味着模型有专门的机制来确定应该何时更新隐状态,以及应该何时重置隐状态。
重置门与更新门
我们把它们设计成(0,1)区间中的向量,这样我们就可以进行凸组合。重置门允许我们控制“可能还想记住”的过去状态的数量;更新门将允许我们控制新状态中有多少个是旧状态的副本。
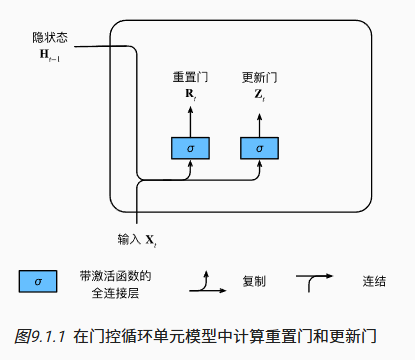
我们来看一下门控循环单元的数学表达。对于给定的时间步$t$,假设输入是一个小批量 $X_t \in \mathbb{R}^{n \times h}$ (样本个数$n$,输入个数$d$),上一个时间步的隐状态是 $H_{t−1} \in \mathbb{R}^{n \times h}$ (隐藏单元个数$h$)。那么,重置门$R_t\in \mathbb{R}^{n \times h}$和 更新门$Z_t∈\mathbb{R}^{n \times h}$的计算如下所示:
$$
R_t = \sigma(X_t W_{xr} + H_{t-1} W_{hr} + b_r) = \sigma(W_{r} \cdot[H_{t-1}, X_{t}] + b_{r})
$$
$$
Z_t = \sigma(X_t W_{xz} + H_{t-1} W_{hz} + b_z) = \sigma(W_{z} \cdot[H_{t-1}, X_{t}] + b_{z})
$$
其中 $W_{xr}, W_{xz} \in \mathbb{R}^{d \times h}$ 和 $W_{hr}, W_{hz} \in \mathbb{R}^{h \times h}$ 是权重参数,$b_r, b_z \in \mathbb{R}^{1 \times h}$ 是偏置参数。请注意,在求和过程中会触发广播机制。我们使用 $\texttt{sigmoid}$ 函数将输入值转换到区间 $(0, 1)$
候选隐状态
接下来,让我们将重置 $\mathbf{R}_t$ 与常规隐状态更新机制集成,得到在时间步 $t$ 的候选隐状态(candidate hidden state) $\tilde{\mathbf{H}}_t \in \mathbb{R}^{n \times h}$:
$$
\tilde{\mathbf{H}}t = \tanh(\mathbf{X}t \mathbf{W}{zh} + (\mathbf{R}t \odot \mathbf{H}{t-1}) \mathbf{W}{hh} + \mathbf{b}h) = \tanh(W{h} \cdot [R_{t} \cdot H_{t-1 }, X_{t}]+b_{h})
$$
其中 $\mathbf{W}{zh} \in \mathbb{R}^{d \times h}$ 和 $\mathbf{W}{hh} \in \mathbb{R}^{h \times h}$ 是权重参数,$\mathbf{b}_h \in \mathbb{R}^{1 \times h}$ 是偏置项,符号 $\odot$ 是 Hadamard 积(按元素乘积)运算符。在这里,我们使用 $\tanh$ 非线性激活函数来确保候选隐状态中的值保持在区间 $(-1, 1)$ 中。
$\mathbf{R}t \odot \mathbf{H}{t-1}$ 的元素相乘可以减少以往状态的影响。每当重置门 $\mathbf{R}_t$ 中的项接近 1 时,我们恢复一个普通的循环神经网络。对于重置门 $\mathbf{R}_t$ 中所有接近 0 的项,候选隐状态是以 $\mathbf{X}_t$ 作为输入的多层感知机的结果。因此,任何预先存在的隐状态都会被重置为默认值。
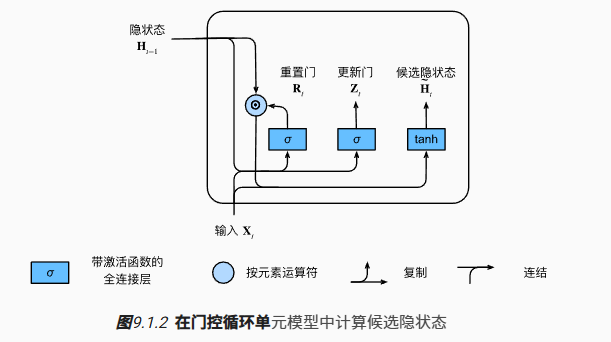
隐状态
上述的计算结果只是候选隐状态,我们仍然需要结合更新门 $\mathbf{Z}_t$ 的效果。这一步确定新的隐状态 $\mathbf{H}t \in \mathbb{R}^{n \times h}$ 在多大程度上来自旧的状态 $\mathbf{H}{t-1}$ 和新的候选状态 $\tilde{\mathbf{H}}_t$。更新门 $\mathbf{Z}t$ 仅需要在 $\mathbf{H}{t-1}$ 和 $\tilde{\mathbf{H}}_t$ 之间进行按元素的凸组合就可以实现这个目标。这就得出了门控循环单元的最终更新公式:
$$
\mathbf{H}_t = \mathbf{Z}t \odot \mathbf{H}{t-1} + (1 - \mathbf{Z}_t) \odot \tilde{\mathbf{H}}_t
$$
每当更新门 $\mathbf{Z}_t$ 接近 1 时,模型就倾向只保留旧状态。此时,来自 $\mathbf{X}_t$ 的信息基本上被忽略,从而有效地跳过了依赖链中的时间步 $t$。相反,当 $\mathbf{Z}_t$ 接近 0 时,新的隐状态 $\mathbf{H}_t$ 就会接近候选隐状态 $\tilde{\mathbf{H}}_t$。
这些设计可以帮助我们处理循环神经网络的梯度消失问题,并更好地捕捉时间步距离很长的序列历史依赖关系。例如,如果整个子序列的所有时间步的更新门都接近于 1,则无论序列的长度如何,在序列起始时间步的旧隐状态都将很容易保留并传递到序列末。
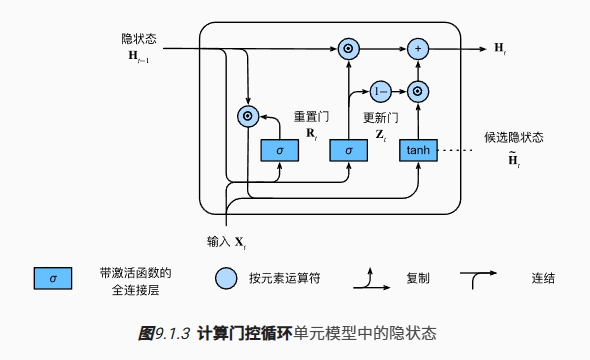
总之,门控循环单元具有以下显著特征:
- 重置门有助于捕获序列中的短期依赖关系,控制当前输入和前一隐藏状态的结合方式
- 更新门有助于捕获序列中的长期依赖关系,决定了前一时刻隐藏状态中的信息保留多少
[!question] 为什么RNN中通常喜欢用 tanh 作为激活函数?
- 与其他激活函数(如ReLU)相比,tanh在梯度计算和数值稳定性方面较为稳定。尽管ReLU在某些任务上表现优越(特别是在避免梯度消失的问题上),但其输出不对称,且在某些情况下会导致“梯度爆炸”或“死神经元”(对于负输入始终输出0)。相比之下,tanh更平滑,且避免了ReLU中可能遇到的一些数值不稳定问题。
- tanh的输出范围是 [-1, 1],它是一个对称的激活函数。这意味着它可以处理负值和正值,这对于在RNN中捕捉和传递信息非常重要。相对而言,sigmoid函数的输出范围是 [0, 1],这可能会限制信息的传递,因为它不能表示负数。