Transformer论文阅读笔记
主要的序列转导模型是基于复杂的循环或卷积神经网络,包括一个编码器和一个解码器。表现最好的模型还通过注意机制连接编码器和解码器。我们提出了一个新的简单的网络架构,Transformer,完全基于注意力机制,完全摒弃递归和卷积。在两个机器翻译任务上的实验表明,这些模型在质量上更优越,同时更具并行性,并且需要更少的训练时间。我们的模型在WMT 2014英语-德语翻译任务上实现了28.4 BLEU,比现有的最佳结果(包括集合)提高了2个BLEU以上。我们通过将Transformer成功地应用于具有大量和有限训练数据的英语选区解析,证明了它可以很好地推广到其他任务。
intro
- 介绍主流序列建模和传导问题方法——基于RNN
- RNN介绍与优缺点分析
- 缺点:$h_{t}$ 时序生成,因此无法并行化;存在长时记忆问题;内存开销较大
- Attention与RNN结合使用,将编码器传导到解码器
- 提出Transformer,可以进行并行化
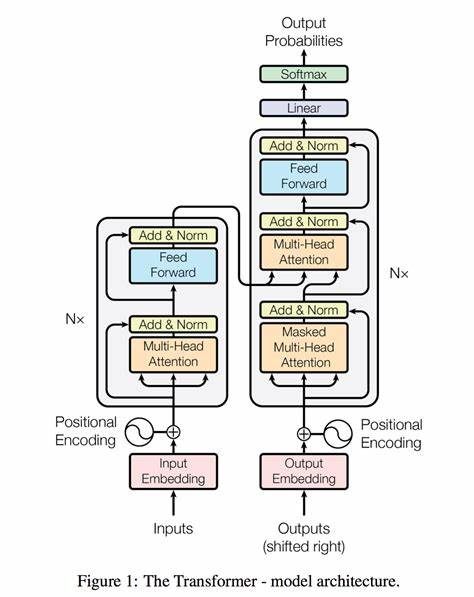
相关工作 (background)
- 卷积网络对长序列难以建模学习,但是有多个通道可以做不同的识别
- 如果使用注意力机制就可以减少操作数
- 自注意力机制
- memory network
模型
编码器:将 $(x_{1},x_{2},\dots,x_{n})$ 编码成 $\mathbf{z}=(z_{1},\dots,z_{n})$ ,其中 $z_{t}$ 表示 $x_{t}$ 的向量表示
解码器:接收编码器输出,生成 $(y_{1},\dots,y_{m})$ 序列,其中解码器每次生成下一个符号时均使用之前生成的符号作为附加输入(自回归)
编码器
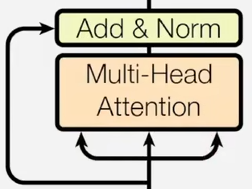
- 多头自注意力层
- 前馈网络(MLP)
- 残差连接
- 层归一化
- $LayerNorm(x + Sublayer(x))$
每一层输出均为512,方便残差连接
LayerNorm
二维情况:
对每个样本做标准化
三维情况: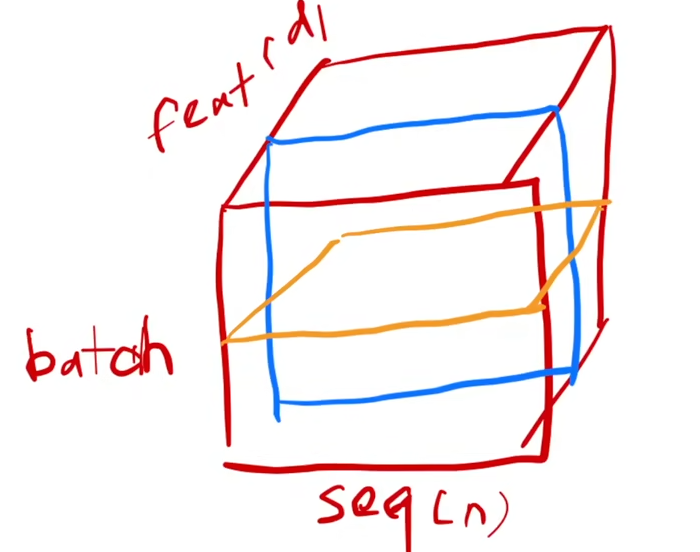
BatchNorm
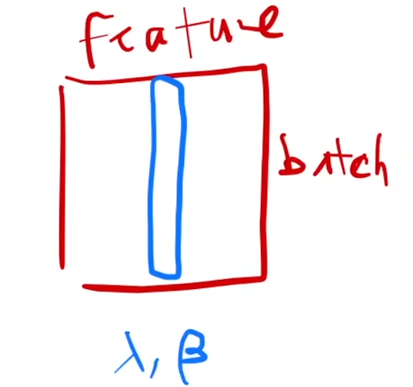
二维情况:
计算同一个feature在一个batch的均值,方差,然后标准化。
对于测试,则将测试集上同一个feature的所有数据计算均值和方差
三维情况: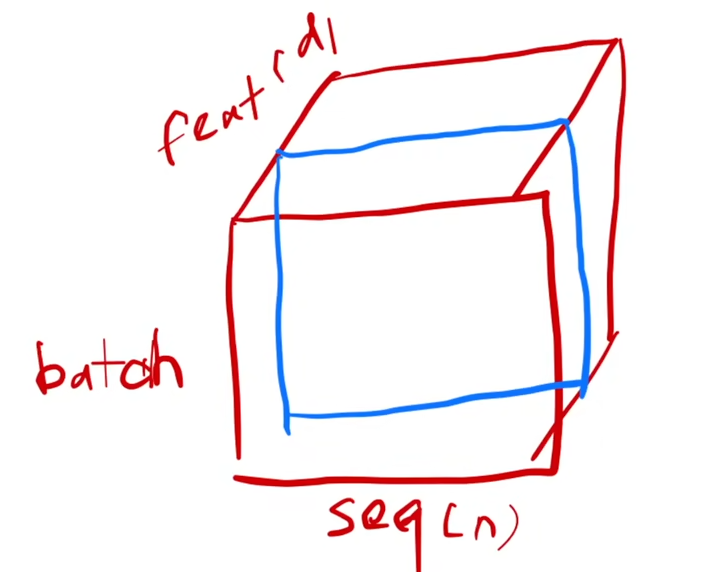
对比
LayerNorm:
- 计算同一个样本均值方差,比较稳定

BatchNorm:
- 当样本数量少(小批量)的时候,均值和方差会剧烈波动
解码器
- 多头自注意力
- 掩码注意力:当前的输出依赖当前与之前的输入,保证训练和预测一致
举个例子:
对于Decoder来说,第一个输入是一个[<Begin>]开始符,然后需要预测出I;然后第二个输入是[<Begin>, I],需要预测第二个…以此类推
Decoder 可以在训练的过程中使用 Teacher Forcing 并且并行化训练,即将正确的单词序列 (<Begin> I have a cat) 和对应输出 (I have a cat <end>) 传递到 Decoder。那么在预测第 i 个输出时,就要将第 i+1 之后的单词掩盖住,注意 Mask 操作是在 Self-Attention 的 Softmax 之前使用的。
注意力
注意函数可以描述为将查询和一组键值对映射到输出,其中查询query、键key、值value和输出output都是向量。输出是作为值的加权和计算的,其中分配给每个值的权重是由查询与相应键的兼容性(相似度)函数计算的。
随着q不一样,相似度不同,因此对应的$\alpha$权重也不一样
scaled dot-product attention
输入由维度 $d_{k}$ 的query和key以及维度 $d_{v}$ 的值组成。我们计算query与所有key的点积,然后每个都除以 $\sqrt{ d_{k} }$ ,并应用softmax求出权重。使用矩阵乘法可以得到下式:
$$
Attention(Q,K,V)=softmax\left( \frac{QK^T}{\sqrt{ d_{k} }} \right)V
$$
再将权重作用于value上得到输出
常见的注意力机制
- 加性注意力:使用一个前馈网络来计算
- 点乘注意力:同上
点乘需要除以 $\sqrt{ d_{k} }$ ,当 $d_{k}$ 较小的时候相似,但是如果较大时,向量的差距会变大,这样乘的时候梯度会变小,可能会跑不动
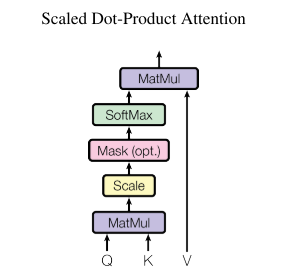
掩码
对于$Q_{t}$的计算,将$k_{t},\dots,k_{n}$这些不知道的值换成一个很大的负数,这样得到的权重就会趋近于0
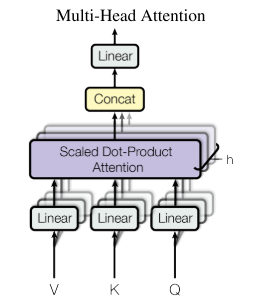
多头注意力
这一块看李宏毅的更清楚
类似于多个卷积核的思想,想要学习不同的模式
多头注意允许模型在不同位置共同注意来自不同表示子空间的信息。对于单一注意力头,平均会抑制这一点
投影到低的维度,这样有更多的参数可以学习
$$
MultiHead(Q,K,V) = Concat(head_{1},\dots,head_{h})W^O
$$
其中
$$
head_{i}=Attention(QW^Q_{i},KW^K_{i},VW^V_{i})
$$
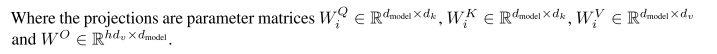
- base:8个头
- big:16个头

详细介绍
举个栗子: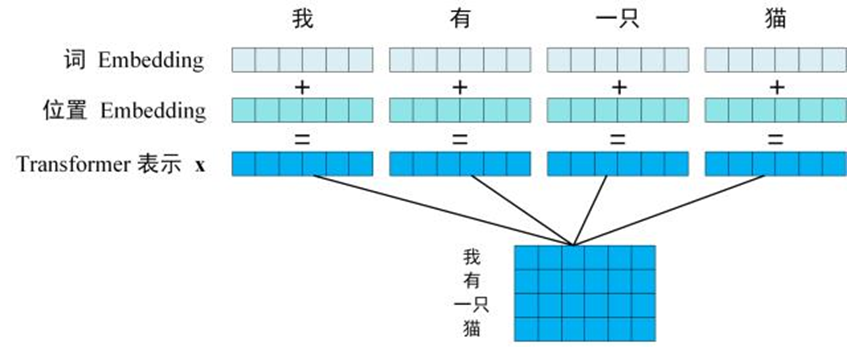
有了这个矩阵后,需要计算Q、K、V: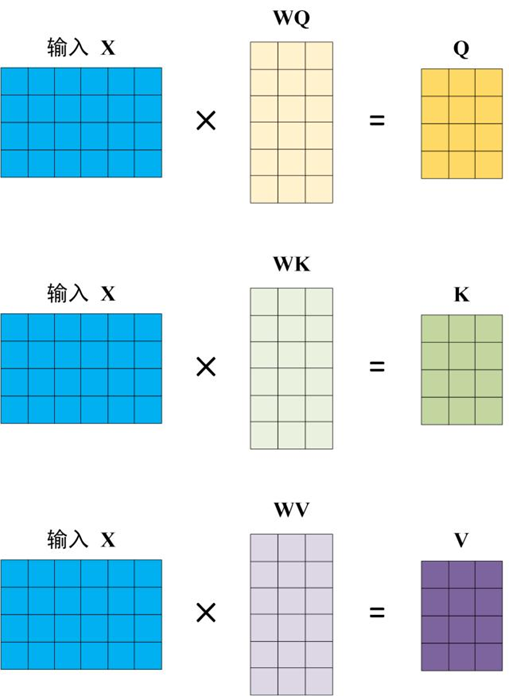
随后需要将Q矩阵和K矩阵进行相乘,再过个softmax(和归一化),得到对应的注意力矩阵: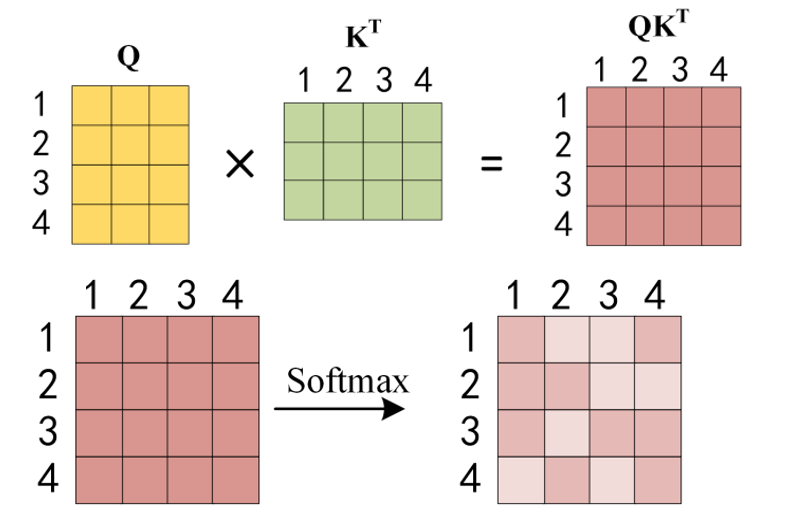
将$QK^T$注意力矩阵与$V$相乘,得到结果: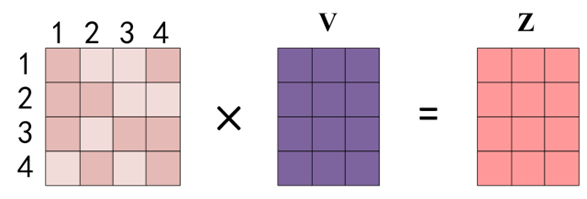
对于多头情况,只需要对同一个输入过不同的self-attention,然后把输出拼起来再过一次全连接即可: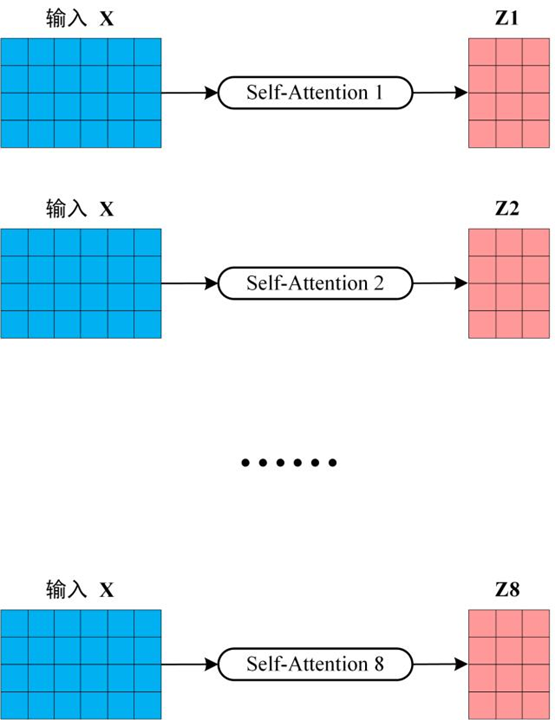
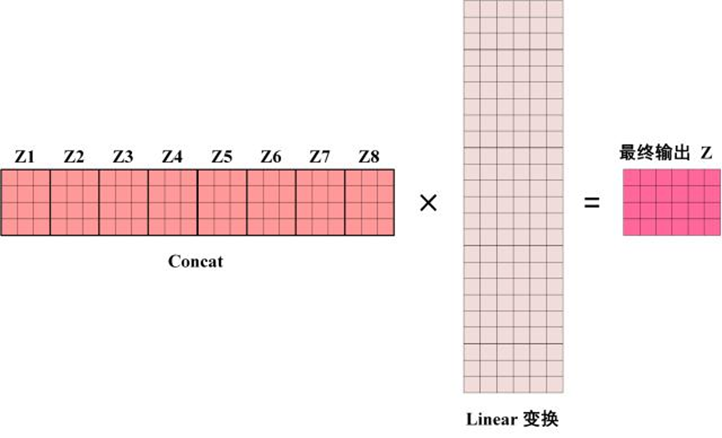
注意力机制运用
Transformer以三种不同的方式使用多头注意:
• 在“编码器-解码器注意”层中,查询来自前一个解码器层,而记忆键和值来自编码器的输出。这允许解码器中的每个位置都参与输入序列中的所有位置。这模仿了序列到序列模型中典型的编码器-解码器注意机制。
• 编码器包含自注意力机制层。在自注意力机制层中,所有的键、值和查询都来自同一个地方,在这种情况下,是编码器中前一层的输出。编码器中的每个位置都可以处理编码器前一层中的所有位置。
三个输入分别表示 key, value, query,是由同一个句子经过编码后转化的向量矩阵,再经过权重矩阵得到
• 类似地,解码器中的自注意力机制层允许解码器中的每个位置关注解码器中的所有位置,直至并包括该位置。我们需要防止解码器中的向左信息流以保持自回归特性。我们通过屏蔽(设置为−∞) softmax输入中对应于非法连接的所有值来实现缩放点积注意力。
前馈网络
除了注意子层之外,编码器和解码器中的每一层都包含一个完全连接的前馈网络,该网络分别相同地应用于每个位置。这包括两个线性转换,中间有一个ReLU激活。
每个词就是一个position,使用MLP对每一个词作用一次
$$
FFN(x) = \max(0, xW_{1}+b_{1})W_{2}+b_{2}
$$
虽然线性变换在不同位置上是相同的,但它们在每一层之间使用不同的参数。另一种描述它的方式是两个核大小为1的卷积。输入和输出的维数$d_{model} = 512$,内层的维数$d_{ff} = 2048$。
意思是先把512投影成2048,然后由于存在残差连接,故需要将2048再投影成512
attention:抓取整个序列的内容进行汇聚
MLP:对汇聚的信息进行分别处理
对比Transformer和RNN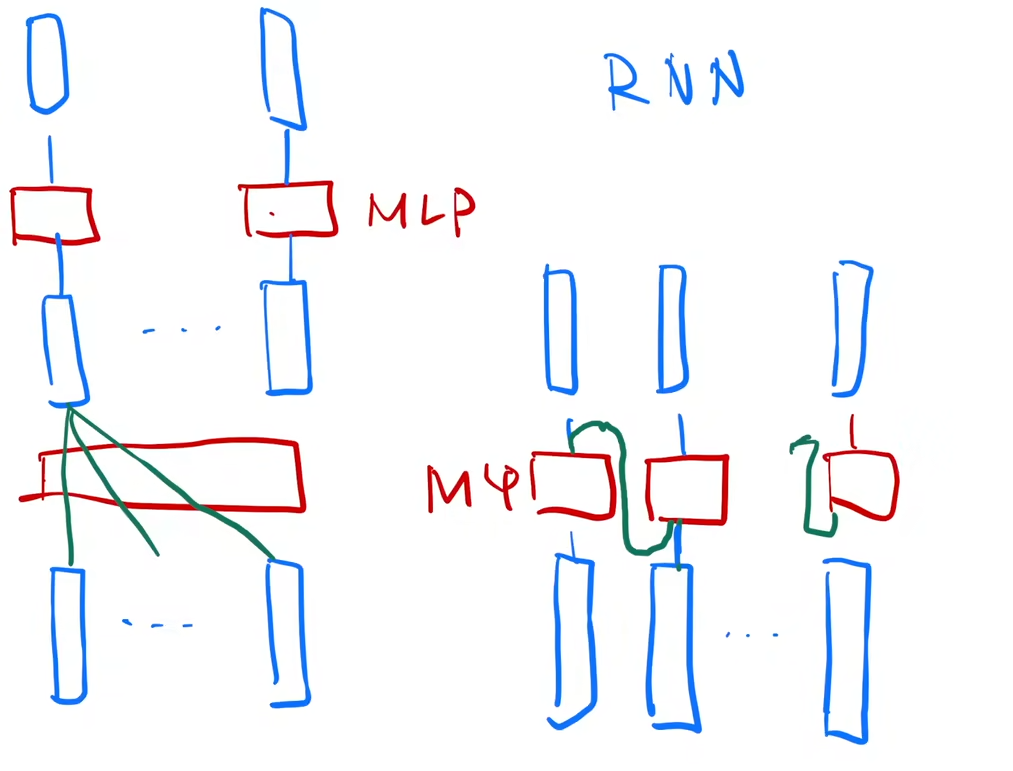
Embedding
将token映射成向量
与其他序列转导模型类似,我们使用learned embeddings将输入token和输出token转换为维度 $d_{model}$ 的向量。
我们还使用usual learned 线性变换和softmax函数将解码器输出转换为预测的下一个token概率。在我们的模型中,我们在两个嵌入层和pre-softmax线性变换之间共享相同的权重矩阵。在嵌入层中,我们将这些权重乘以 $\sqrt{d_{model}}$ 进行归一化。
Position Encoding
对于时序顺序,attention不会处理,因此需要用位置编码,在输入里面加入时序信息
在原论文中采用正弦和余弦函数进行位置编码,任何一个值,可以用长向量来表示,然后再和原本的向量相加,于是就将时序信息加入到数据中。向量相加,维度不变,长度方向改变
$$
PE_{(pos,2i)}=\sin (pos/(10000^{2i/dmodel}))
$$
$$
PE_{(pos,2i+1)}=\cos (pos/(10000^{2i/dmodel}))
$$
Why Self-Attention

一个是每层的总计算复杂度。另一个是可以并行化的计算量,通过所需的最小顺序操作数来衡量。
第三个是网络中远程依赖关系之间的路径长度。学习远程依赖关系是许多序列转导任务中的关键挑战。影响学习这种依赖关系能力的一个关键因素是网络中向前和向后信号必须经过的路径长度。输入和输出序列中任意位置组合之间的路径越短,学习远程依赖关系[12]就越容易。因此,我们还比较了由不同层类型组成的网络中任意两个输入和输出位置之间的最大路径长度
实验
我们在标准的WMT 2014英语-德语数据集上进行训练,该数据集由大约450万句对组成。句子使用字节对编码进行编码,具有大约37000个标记的共享源-目标词汇表。对于英语-法语,我们使用了更大的WMT 2014英语-法语数据集,该数据集由36M个句子组成,并将标记拆分为32000个单词块的词汇。句子对按近似序列长度进行批处理。每个训练批包含一组句子对,其中包含大约25000个源标记和25000个目标标记。

我们将Dropout应用于每个子层的输出,然后将其添加到子层输入并归一化。此外,我们将dropout应用于编码器和解码器堆栈中的嵌入和位置编码之和。对于基本模型,我们使用$P_{drop} = 0.1$的速率。
在训练过程中,我们使用值为$ϵ_{ls} = 0.1$的标签平滑。这损害了困惑,因为模型学会了更不确定,但提高了准确性和BLEU分数