CLIP论文阅读笔记
Learning Transferable Visual Models From Natural Language Supervision
利用自然语言的监督信号,训练一个迁移性能好的视觉模型
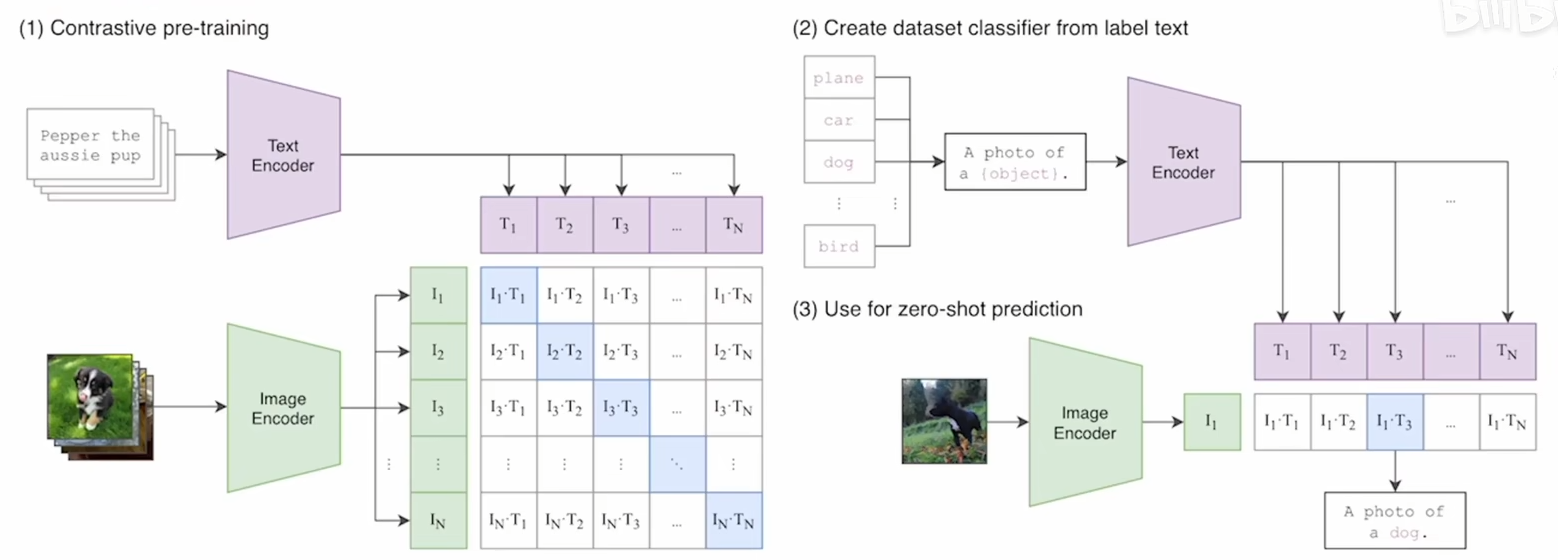
zero-shot
多模态
利用自然语言提供的信号训练
在图片-文本对上做对比学习
- 正样本:图片文本对(对角线元素) $n$
- 负样本:非对角线$n^2-n$
prompt template
刚刚只是做训练,得到了特征,还没有分类头。于是需要 prompt template 进行帮助分类
以ImageNet为例,把每个类对应的每一个单词组合起来变成每一个句子(eg. 这是一架飞机),再进行encoder,得到文本的特征
[!ques] 为什么不直接抽取单词的文本特征
训练的时候是丢一个句子文本进行训练,因此如果直接抽取单词的特征,那么就跟训练的时候不太一样了,就不太符合训练特征
拿图片特征与文本特征计算余弦相似度,最相似的对应图片对应的类
彻底摆脱了categorical label的限制,不需要一个提前定好标签的列表了。任意给一张照片,都可以通过给模型喂不同的文本句子,从而判断有没有我感兴趣的物体
把视觉和文字的语义特征联系到一起,因此迁移效果强,语义分类效果好
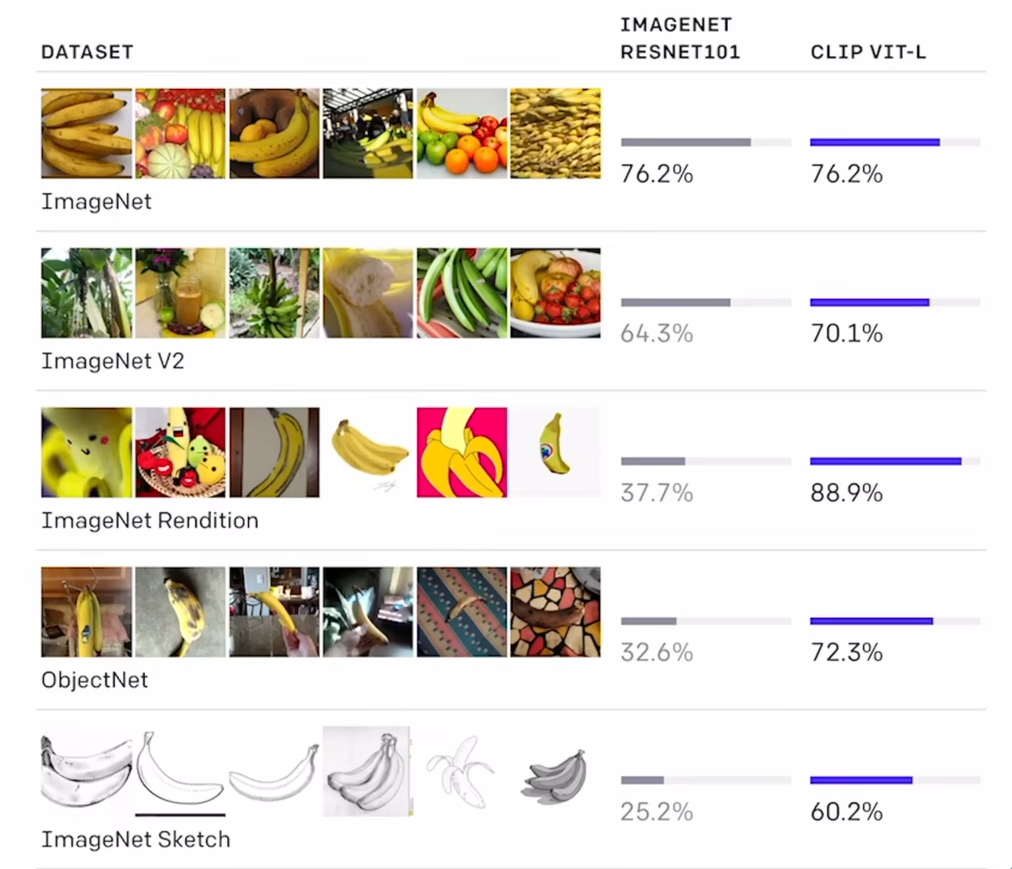
即使domain变化巨大,分类效果还是很好
效果:
图像生成


物体检测
摆脱基础类限制,可以得到更丰富的语义信息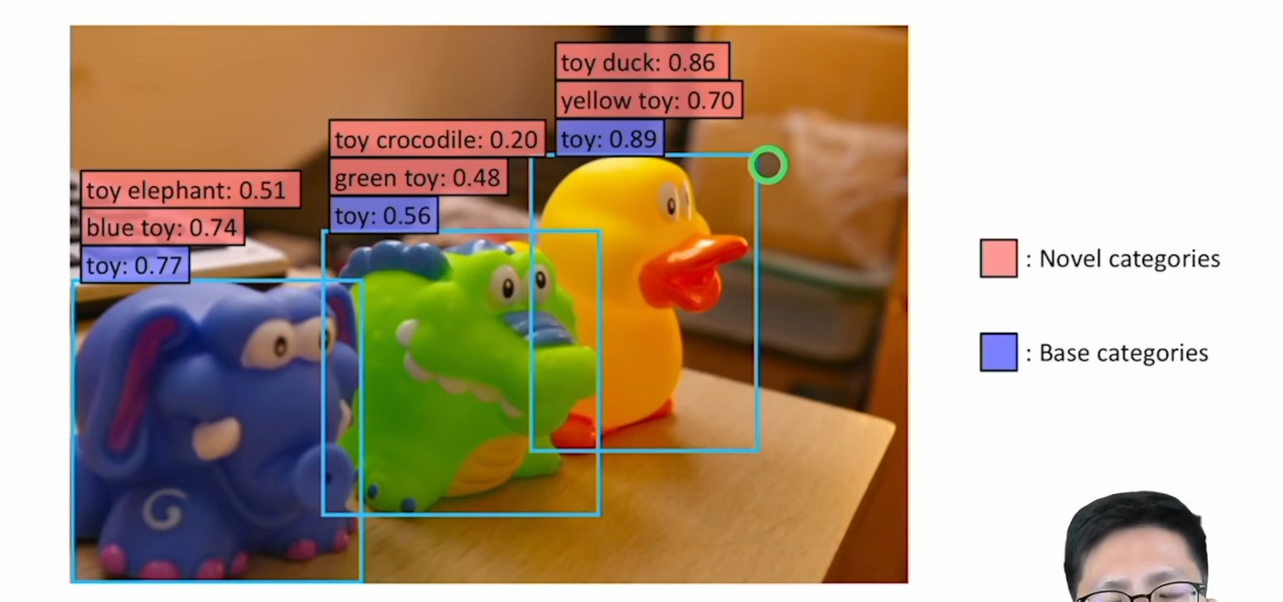
ocr:

摘要
最先进的计算机视觉系统经过训练可以预测一组固定的预定对象类别。这种受限的监督形式限制了它们的通用性和可用性,因为需要额外的标记数据来指定任何其他视觉概念。直接从原始文本中学习图像是一种很有前途的替代方案,它利用了更广泛的监督来源。我们证明,预测哪个标题与哪个图像对应的简单预训练任务是一种高效且可扩展的方法,可以在从互联网收集的 4 亿对(图像、文本)数据集上从头开始学习 SOTA 图像表示。预训练后,使用自然语言来引用学习的视觉概念(或描述新的视觉概念),从而实现模型零样本传输到下游任务。 我们通过对 30 多个不同的现有计算机视觉数据集进行基准测试来研究这种方法的性能,涵盖 OCR、视频中的动作识别、地理定位和许多类型的细粒度对象分类等任务。该模型可以轻松地迁移到大多数任务,并且通常可以与完全监督的基线竞争,而无需任何数据集特定的训练。 例如,我们在 ImageNet 零样本上匹配原始 ResNet-50 的准确性,而无需使用其所训练的 128 万个训练样本中的任何一个。 我们在 https://github.com/OpenAI/CLIP 发布了代码和预训练模型权重。
Intro
直接从原始文本中学习的预训练方法在过去几年中彻底改变了 NLP。自回归和掩码语言建模等任务无关的目标在计算、模型容量和数据方面已经扩展了多个数量级,稳步提高了能力。 “文本到文本”作为标准化输入输出接口的发展,使任务无关架构能够零样本传输到下游数据集消除了对专门输出头或数据集特定定制的需要。 像 GPT-3这样的旗舰系统现在在许多具有定制模型的任务中具有竞争力,同时几乎不需要或不需要特定于数据集的训练数据。
不需要花费心思设计针对某一具体任务的输出头/针对数据集的特殊处理
大规模没有标注的数据反而比有标注的数据更好
从NLP扩展到CV
自监督训练
虽然作为概念证明令人兴奋,但使用自然语言监督进行图像表示学习仍然很少。这可能是因为在普通基准测试中演示的表现比替代方法低得多。
- 例如,Li等人(2017)在零样本学习设置下在ImageNet上仅达到11.5%的准确率。这远低于目前技术水平的88.4%的准确率(Xie et al., 2020)。它甚至低于经典计算机视觉方法的50%准确率(Deng et al., 2012)。
相反,对薄弱监管的范围更窄但目标更明确的使用改善了表现。
- Mahajan等人(2018)表明,预测Instagram图像上与imagenet相关的标签是一项有效的预训练任务。当对ImageNet进行微调时,这些预训练模型的准确率提高了5%以上,并改善了当时的整体技术水平。Kolesnikov等人(2019)和Dosovitskiy等人(2020)也通过预训练模型来预测带有噪声标记的JFT-300M数据集的类别,在更广泛的迁移基准集上取得了巨大的收益。
这条工作路线代表了当前实用主义的中间立场,即从有限数量的监督“黄金标签”和从几乎无限数量的原始文本中学习之间进行学习。
- 然而,这并非没有妥协。两者的作品都经过精心设计,并在工艺限制下,他们的监督类分别为1000类和18291类。自然语言能够通过其通用性来表达并监督更广泛的视觉概念。这两种方法还使用静态softmax分类器来执行预测,并且缺乏动态输出的机制。这严重削弱了它们的灵活性,限制了它们的“零样本学习”能力。
规模很重要
- 弱监督学习:大规模数据集
- 我们创建了一个包含4亿对(图像,文本)的新数据集,并证明了从头开始训练的ConVIRT的简化版本,我们称之为CLIP,用于对比语言-图像预训练
- 我们通过训练一系列八个模型来研究CLIP的可扩展性,这些模型跨越了近2个数量级的计算,并观察到迁移表现是计算的平滑可预测函数
ConVIRT简化版本
迁移学习效果与模型大小有关
linear-probe
更加稳健
Approch
我们方法的核心思想是从自然语言的监督中学习感知。
这一行的共同之处并不是使用特定方法的任何细节,而是对自然语言作为训练信号的欣赏。所有这些方法都是从自然语言监督视觉中学习的。尽管早期的工作在使用主题模型和n-gram表示时与自然语言的复杂性作斗争,但深度上下文表示学习的改进表明,我们现在有了有效利用这种丰富的监督来源的工具。
- 潜在的优势
- 与用于图像分类的标准众包标签相比,扩展自然语言监督要容易得多,因为它不要求注释采用经典的“机器学习兼容格式”,例如标准的1-of-N多数投票“金标”。相反,研究自然语言的方法可以被动地从互联网上大量文本的监督中学习。
- 与大多数无监督或自监督学习方法相比,从自然语言中学习也有重要的优势,因为它不仅“只是”学习表征,而且还将表征与语言联系起来,从而实现灵活的零样本学习迁移。在接下来的小节中,我们将详细介绍我们选定的具体方法。
需要足够大的数据集和足够好的标注WIT(WebImageText)
预训练方法
我们发现训练效率是成功扩展自然语言监督的关键,我们根据这个指标选择了最终的预训练方法。
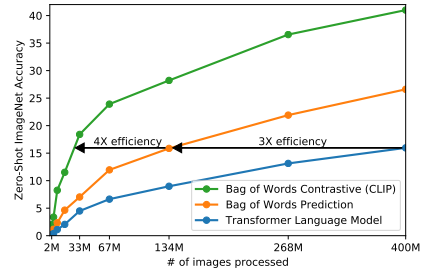
我们最初的方法类似于VirTex,从头开始联合训练图像CNN和文本转换器来预测图像的标题。然而,我们在有效扩展这种方法时遇到了困难。在图2中,我们展示了一个6300万个参数的转换器语言模型,它已经使用了两倍的ResNet-50图像编码器的计算,它学习识别ImageNet类别的速度比预测相同文本的单词袋编码的简单基线慢三倍。
这两种方法有一个关键的相似之处。他们试图预测每幅图片的准确文字。这是一项艰巨的任务,因为与图像同时出现的描述、评论和相关文本种类繁多。
- 生成变成了判别
最近在图像对比表征学习方面的工作发现,对比目标比其等效的预测目标可以更好地学习表征(Tian et al., 2019)。其他研究发现,尽管图像的生成模型可以学习高质量的图像表示,但与具有相同表现的对比模型相比,它们需要超过一个数量级的计算量(Chen等人,2020a)。注意到这些发现,我们探索了训练一个系统来解决潜在的更容易的代理任务,即只预测哪个文本作为一个整体与哪个图像配对,而不是该文本的确切单词。从相同的词袋编码基线开始,我们将预测目标替换为图2中的对比目标,并观察到零样本学习转移到ImageNet的效率进一步提高了4倍。
- 蓝线:逐字逐句预测
- 黄线:预测抽成的特征
- 绿色:判断是不是图片文本对
训练

单模态正样本变成多模态正样本
编码器均不训练
使用线性投射层
随机裁剪
视觉部分:ResNet/Vision Transformer
文本部分:Transformer
混精度训练,省内存,提高训练速度
相似度在多GPU计算
在更大尺寸图片上fine-tune
实验
零样本迁移
在计算机视觉中,零样本学习通常是指对图像分类中未见过的物体类别进行泛化的研究(Lampert et al., 2009)。相反,我们在更广泛的意义上使用这个术语,并研究对未见过的数据集的泛化。我们将其作为执行看不见的任务的代理,正如Larochelle等人(2008)在零数据学习论文中所期望的那样。
虽然无监督学习领域的许多研究都集中在机器学习系统的表示学习能力上,但我们鼓励研究零样本转移作为衡量机器学习系统任务学习能力的一种方法。在此视图中,数据集评估特定分布上任务的表现。
然而,许多流行的计算机视觉数据集是由研究界创建的,主要是作为指导通用图像分类方法开发的基准,而不是衡量特定任务的表现。虽然可以合理地说SVHN数据集测量了谷歌街景照片分布上的街道号码转录任务,但尚不清楚CIFAR-10数据集测量的是什么“真正的”任务。然而,很明显,CIFAR-10是从TinyImages中提取的分布(Torralba et al., 2008)。在这类数据集上,零样本学习转移更多的是评价CLIP对分布转移和领域泛化的鲁棒性,而不是任务泛化。
prompt engineering and ensembling
大多数标准图像分类数据集都将命名或描述类别的信息视为事后的想法,这使得基于自然语言的零样本 转移成为可能。绝大多数数据集仅使用标签的数字id对图像进行注释,并包含将这些id映射回其英文名称的文件。有些数据集,如Flowers102和GTSRB,在其发布版本中似乎根本不包括这种映射,从而完全防止了零样本 传输对于许多数据集,我们观察到这些标签的选择可能有些随意,并且没有预料到与零样本 转移相关的问题,这依赖于任务描述以成功转移
一个常见的问题是一词多义。当类的名称是提供给CLIP的文本编码器的唯一信息时,由于缺乏上下文,它无法区分指的是哪个词义。在某些情况下,同一个单词的多个含义可能会作为不同的类别包含在同一个数据集中!这发生在ImageNet中,它包含建筑起重机和飞行起重机。另一个例子是在Oxford-IIIT Pet数据集的类别中发现的,从上下文来看,单词boxer显然指的是一种狗,但对于缺乏上下文的文本编码器来说,它很可能指的是一种运动员。
我们遇到的另一个问题是,在我们的预训练数据集中,与图像配对的文本只是一个单词的情况相对较少。通常文本是一个完整的句子,以某种方式描述图像。为了帮助弥合这种分布差距,我们发现使用提示模板“A photo of A {label}.”是一个很好的默认值,可以帮助指定文本是关于图像的内容(解决了歧义性的问题)。这通常比仅使用标签文本的基线提高表现。
例如,仅仅使用这个提示符就可以将ImageNet上的准确率提高1.3%。类似于围绕GPT3的“提示工程”讨论(Brown et al., 2020;Gao等人,2020),
- 通过为每个任务定制提示文本,可以显著提高零样本表现。
下面是一些不详尽的例子。我们在几个细粒度的图像分类数据集中发现,它有助于指定类别。例如,在Oxford-IIIT Pets中,使用”A photo of a {label}, a type of pet.” 来帮助提供背景,效果很好。同样,在Food101上指定一种食物类型和在FGVC飞机上指定一种飞机类型也有所帮助。对于OCR数据集,我们发现在要识别的文本或数字周围加上引号可以提高表现。最后,我们发现在卫星图像分类数据集中,它有助于指定图像是这种形式,我们使用“a satellite photo of a {label}.”的变体
我们还尝试了多个零样本分类器的集成,作为提高性能的另一种方法。 这些分类器是通过使用不同的上下文提示来计算的,例如“‘A photo of a big {label}”和“A photo of a small {label}”。 我们在嵌入空间而不是概率空间上构建集成。 这使我们能够缓存一组平均文本嵌入,以便在分摊到许多预测时,整体的计算成本与使用单个分类器的成本相同。
zero-shot
我们观察到许多生成的零样本分类器的集成可以可靠地提高性能并将其用于大多数数据集。 在 ImageNet 上,我们集成了 80 个不同的上下文提示,这比上面讨论的单个默认提示额外提高了 3.5% 的性能。 当综合考虑时,快速工程和集成可将 ImageNet 的准确性提高近 5%。 在图 4 中,我们直观地看到了即时工程和集成如何改变一组 CLIP 模型的性能,与直接嵌入类名的无上下文基线方法相比,如 Li 等人所做的那样。
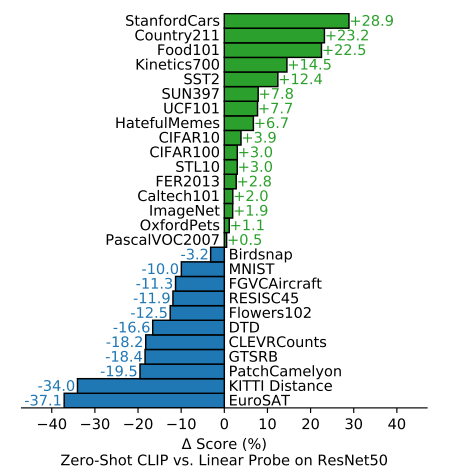
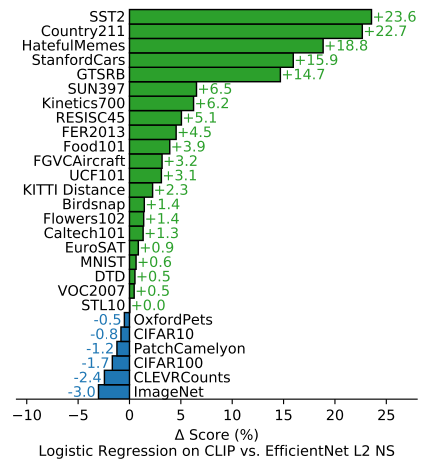
对给物体分类的数据集,表现得会更好;但要是更难的数据集,会表现更差,因为难以用文本表示(需要特定语义知识)
few-shot
把图片的编码器冻结,做Linear Probe
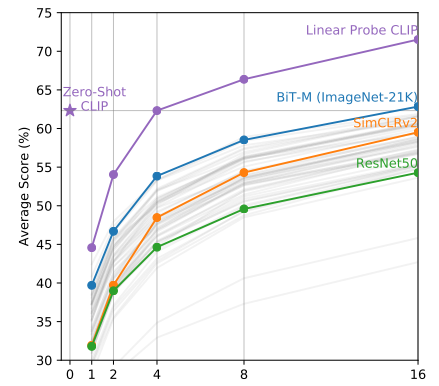
每条曲线是二十个数据集的合并
特征学习
linear-probe: 把预训练的模型冻结,再训练一个线性分类头(最后一层)
fine-tune: 把整个网络放开,做端到端学习
选择了linear-probe: 为了测试迁移能力,防止下游任务污染编码器
更好反映预训练模型的好坏
越靠近左上角 trade-off做得越好
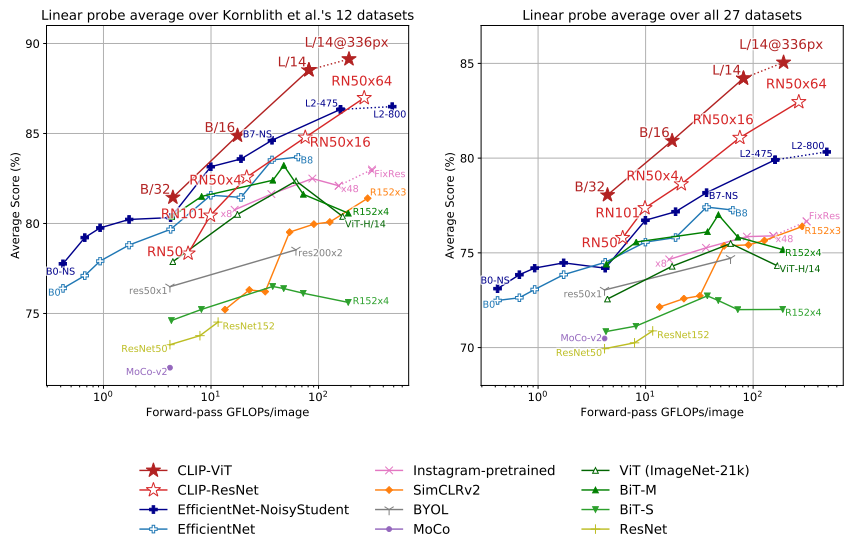
分布偏移也不掉点
不足
训练量逼近SOTA需要扩大1000倍
细分类效果差
抽象概念和更难的任务
OOD问题泛化差
数据利用不高效:自监督和伪标
数据没有清洗,可能有偏见
在部署多模式模型之前,人们需要仔细研究它们在给定背景和领域中的行为
鉴于其零样本功能,CLIP 为数据相对较少的任务提供了显着的优势。然而,对于许多按需监控任务(例如面部识别)来说,存在大型数据集和高性能监督模型。因此,CLIP 对此类用途的相对吸引力较低。 此外,CLIP 不适用于常见的监视相关任务,例如对象检测和语义分割。 这意味着当设计时考虑到这些用途的模型(例如 Detectron2(Wu 等人,2019))广泛使用时,它在某些监视任务中的用途有限
创新
打破固定种类收集的样式
推理模型更方便